

Think raw speed is the only thing that matters in LLMs?
Claude 3.5 Sonnet argues otherwise, trading sub-second streaming for a huge 200,000-token context and stronger vision reasoning.
Released June 20, 2024, it sits between Haiku and Opus, offering faster responses than Opus, better coding and long-document handling, and multimodal input.
This post breaks down the specs, real-world benchmarks, and step-by-step implementation tips so teams can decide when to switch, how to integrate, and what to test first.
Overview of Claude 3.5 Sonnet

Claude 3.5 Sonnet is Anthropic’s mid-tier large language model, released in June 2024. It sits between the lighter Haiku and the unreleased Opus in the Claude 3.5 lineup. What you’re getting here is a meaningful step up from both Claude 3 Opus and Claude 3 Sonnet—faster responses, better reasoning, stronger vision handling—without paying more.
The focus is enterprise work where speed and consistency actually matter. Claude 3.5 Sonnet codes more accurately, chews through long documents without losing the thread, and reads charts and diagrams with fewer mistakes than what came before. Anthropic baked in Constitutional AI guardrails and ran the model through independent safety tests with UK and US AI institutes before launch.
If you’re on Claude 3 Opus, you’re looking at roughly double the speed on most tasks, plus better performance when the model needs to chain together multi-step workflows on its own. Comparing it to GPT-4o or Gemini 1.5 Pro? Claude trades a bit of raw math performance for stronger vision reasoning and a bigger context window. It went live June 20, 2024, through Anthropic’s API, Amazon Bedrock, and Google Cloud Vertex AI.
Core Technical Specifications

Claude 3.5 Sonnet works with a 200,000-token context window. That means you can drop in entire codebases, legal docs, or multi-chapter manuscripts without breaking them into pieces. It’s particularly useful for retrieval-augmented generation workflows and long-form document synthesis where other models force you to chunk and reassemble everything.
The model takes both text and images, so it’s genuinely multimodal. Graphs, screenshots, diagrams, scanned documents—it reads them alongside your prompts.
Anthropic says Claude 3.5 Sonnet runs about twice as fast as Claude 3 Opus internally. But external tests show response times averaging around 14 seconds per request, which is way slower than GPT-4o’s sub-second streaming in a lot of cases. Training data goes through April 2024, so anything after that might produce outdated or made-up answers. Safety stays at ASL-2 risk classification with Constitutional AI alignment, plus ongoing monitoring and pre-deployment testing shared with independent evaluators.
| Specification | Details |
|---|---|
| Context Window | 200,000 tokens |
| Input Modalities | Text and images |
| Speed/Latency | ~14 seconds per request (2x faster than Claude 3 Opus) |
| Safety Classification | ASL-2 with Constitutional AI; pre-deployment testing by UK/US institutes |
| Knowledge Cutoff | April 2024 |
Key Features and Functional Capabilities

Claude 3.5 Sonnet brings an interactive workspace called Artifacts. It displays code, visualizations, and mockups in a split panel next to the chat. Ask for a React component, a reveal.js slide deck, or a data viz, and Artifacts renders it live with separate Code and Preview tabs. It’s built for iteration—you can ask the model to tweak a chart’s layout or fix a bug in generated code, and the panel updates without wiping previous versions. To turn it on, click your account initials, select Feature Preview, and toggle Artifacts On.
Coding accuracy jumped substantially over Claude 3 Opus. 92.0% pass rate on HumanEval (a Python function test set) and a 49% solve rate on SWE-bench Verified, which tests real bug fixes and feature additions. For long documents, the 200,000-token context means you feed in entire textbooks, legal briefs, or transaction logs in one prompt. No splitting required.
Vision improvements let it handle imperfect scans, pull data from charts with overlapping labels, and transcribe text from low-quality images. Useful in retail inventory, logistics docs, and financial report analysis.
Structured output reliability went up too. Claude 3.5 Sonnet generates valid JSON, HTML, and Markdown more consistently, cutting down on post-processing or retry logic in automated pipelines. It also handles autonomous multi-step workflows with a reported 40–54% success rate on tasks needing planning, tool use, and error correction without human intervention. For simpler tasks, internal tests show 78% of vague business questions got usable answers, with twice as many “perfect” responses compared to earlier versions.
Key capabilities:
- High-accuracy code generation and debugging across multiple languages, with persistent error correction through iterative prompts
- Long-form reasoning over 200,000-token inputs for single-call analysis of multi-file projects or years of transaction data
- Multimodal image understanding for chart interpretation, diagram transcription, and visual question answering
- Structured output formatting (JSON, HTML, Markdown) with lower failure rates and cleaner schemas
- Interactive Artifacts workspace for real-time editing and remixing of generated code, visualizations, and written content
Performance Benchmarks
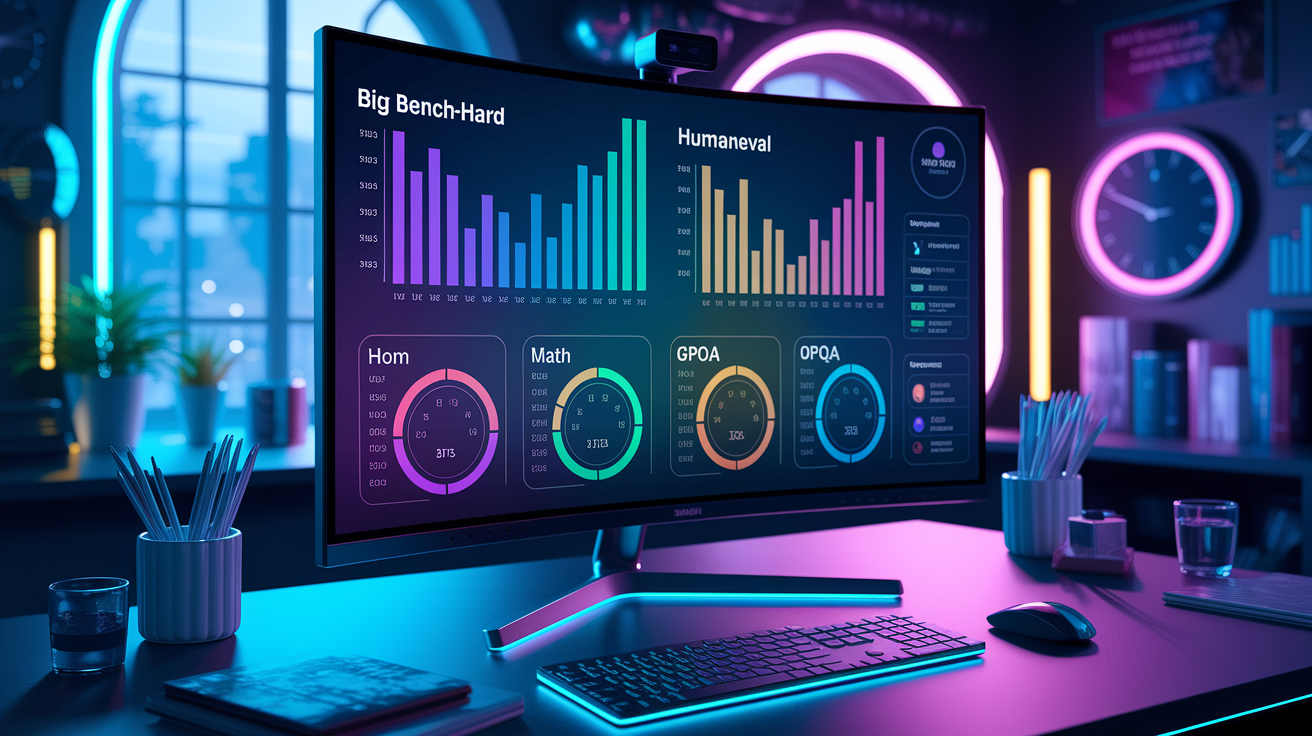
Claude 3.5 Sonnet leads on several reasoning and vision tasks. It trails GPT-4o on advanced math. On BIG-Bench-Hard, a multi-step reasoning test, it scored 93.1%, beating both GPT-4o and Gemini 1.5 Pro. For visual math problems (MathVista), it hit 67.7%, a solid margin over competitors. In coding, it got 92.0% on HumanEval and solved 49% of SWE-bench Verified problems, four percentage points higher than OpenAI’s o1 preview model.
On standard math benchmarks, the model is strong but not dominant. GSM8K (grade-school word problems) showed 96.4% accuracy. The harder MATH benchmark returned 71.1%—nearly six points below GPT-4o’s 76.6%. Graduate-level science questions (GPQA) showed Claude 3.5 Sonnet at 59.4% versus GPT-4o’s 53.6%. MMLU, a 57-subject knowledge test, placed the model around 89–90%, competitive with other frontier models. Internal agentic coding tests reported a 64% solve rate, up from 38% for Claude 3 Opus.
| Benchmark | Claude 3.5 Sonnet Score | Comparison Model Score |
|---|---|---|
| BIG-Bench-Hard (reasoning) | 93.1% | Lower for GPT-4o and Gemini 1.5 Pro |
| HumanEval (Python coding) | 92.0% | GPT-4o: 90.2% |
| MATH (advanced math) | 71.1% | GPT-4o: 76.6% |
| GPQA (graduate science) | 59.4% | GPT-4o: 53.6% |
Comparison to Other Models

Claude 3.5 Sonnet runs roughly twice as fast as Claude 3 Opus on internal tests. That makes it the faster pick for users who previously paid Opus-tier pricing. Compared to the earlier Claude 3 Sonnet, reasoning quality improved by about 10% on complex tasks, and the new model handles autonomous multi-step workflows more reliably. Teams moving from Claude 3 Opus get higher throughput without giving up accuracy on coding or long-document tasks.
Against GPT-4o, Claude 3.5 Sonnet trades speed for context and vision. GPT-4o streams responses at roughly 155 tokens per second with sub-second first-token latency. Claude averages 14 seconds per full response. GPT-4o also leads on pure math (76.6% vs 71.1% on MATH). But Claude’s 200,000-token window is five times larger than GPT-4o’s standard context, and its vision reasoning (especially on MathVista and chart interpretation) beats both GPT-4o and Gemini 1.5 Pro. For input cost, Claude charges $3 per million tokens versus GPT-4o’s $5, a real difference at scale.
Gemini 1.5 Pro offers an even larger context window (up to 2 million tokens in some configurations) and tight integration with Google Cloud services like BigQuery. But in head-to-head coding and reasoning benchmarks, Claude 3.5 Sonnet scores higher on tasks requiring iterative debugging or autonomous problem solving. Gemini’s strength is massive-context document processing and native Google ecosystem workflows. Claude excels at coding assistance, logical reasoning, and cost-efficient input processing. For teams already on AWS or using Anthropic’s API, Claude 3.5 Sonnet typically delivers better value on coding and analysis workloads than Gemini at comparable context lengths.
Pricing and Access

Claude 3.5 Sonnet uses usage-based pricing at $3 per million input tokens and $15 per million output tokens. Volume discounts exist for large deployments, though Anthropic hasn’t published fixed discount tiers publicly. For comparison, personal subscriptions to Claude Pro (web UI with higher limits) cost roughly $20 per month, similar to ChatGPT Plus and other consumer AI subscriptions.
The model is accessible through three primary channels:
- Anthropic API (direct access with API key and Python/Node SDKs)
- Amazon Bedrock (AWS integration with IAM, VPC controls, and enterprise audit logging)
- Google Cloud Vertex AI (available since June 20, 2024, with BigQuery integration and Model Garden tooling)
- Free web UI tier (very limited—around 10 prompts before hitting usage caps; Pro subscription required for regular use)
Bedrock sets practical rate limits of roughly 50 requests or 400,000 tokens per minute. Hitting these ceilings triggers “Too many tokens” errors, so high-throughput production deployments need batching, backoff logic, or multiple API keys. Model versioning (such as claude-3-5-sonnet-20241022) can break integrations when Anthropic updates identifiers, so solid tooling should include fallback logic and version detection.
Practical Use Cases

Organizations use Claude 3.5 Sonnet for coding assistance in DevSecOps pipelines, where it writes tests, debugs legacy code, and generates pull-request-ready snippets. GitLab integrated it into GitLab Duo Chat, serving over 50% of Fortune 100 companies with AI-powered code suggestions and issue resolution. The model’s persistent debugging—where it refines broken code across multiple turns—leads to higher end-to-end success rates and fewer “almost works” patches that still need manual fixes.
In data analysis, teams feed entire schemas, compliance documents, and years of transaction logs into the 200,000-token context to generate summaries, predictions, and visualizations without stitching multiple API calls. Snowflake Cortex uses Claude on Vertex AI to let analysts query proprietary datasets with natural language, combining the model’s reasoning with BigQuery’s scale. For customer support, the model orchestrates multi-step workflows to handle complex inquiries, routing between internal knowledge bases and external APIs to deliver faster resolutions and improved customer experience scores.
Common enterprise applications:
- Software development: writing unit tests, migrating legacy codebases, generating functional prototypes from high-level specs
- Research and business intelligence: analyzing unstructured reports, extracting trends from hundreds of pages of data, drafting structured summaries
- Regulated industries: creating medical documentation, financial compliance reports, and legal briefs while keeping reference material in memory (still requires human review for high-risk outputs)
- Education and training: converting textbooks into interactive lessons, generating quizzes, and building visual study aids
- Retail and logistics: interpreting manifests, cleaning inventory records, and extracting structured data from scanned documents
Implementation Guidance for Developers

Integrating Claude 3.5 Sonnet starts with picking a deployment channel. Anthropic’s API offers the most direct access. Bedrock and Vertex AI provide enterprise features like role-based access controls, VPC integration, and full audit logs. For AWS-heavy teams, Bedrock simplifies IAM and logging. For Google Cloud users, Vertex AI integrates with BigQuery and offers tools like Auto SxS for model evaluation and LangChain support for agent workflows.
Once you’ve selected a platform, authentication follows standard patterns. For Anthropic’s API, you generate an API key from the console, install the anthropic Python library (pip install anthropic), and send requests to the Claude 3.5 Sonnet endpoint. Bedrock and Vertex require cloud-specific credentials (IAM roles or service accounts), but the request structure stays similar. Prompts should use clear system, user, and assistant roles. Structured outputs benefit from explicit instructions like “Return valid JSON with these fields” or “Use Markdown headers for sections.”
To get reliable results and avoid common mistakes, follow these steps:
- Set up your environment by installing the SDK (
pip install anthropicor configure Bedrock/Vertex clients) and securing your API key or cloud credentials. - Authenticate using your chosen platform’s method—API key for Anthropic, IAM role for Bedrock, service account for Vertex AI.
- Send queries with clear role definitions (system: task context, user: the question, assistant: any prior model responses) and specify output format when structure matters (JSON schema, Markdown, code).
- Handle responses by checking for errors, parsing structured outputs, and logging token usage to monitor costs and throughput.
- Refine prompts through iteration—test different phrasings, add examples for few-shot learning, and use the 200,000-token context to include all necessary reference material in one call instead of splitting inputs.
For high-throughput production use, add rate-limit buffers to stay below platform ceilings (Bedrock’s ~50 requests per minute, for instance), add retry logic with exponential backoff, and monitor model version identifiers to catch breaking changes. When deploying long-context workflows, verify that your test harnesses and evaluation pipelines support inputs up to 200,000 tokens, since many standard tools cap at much smaller sizes.
Limitations and Known Challenges

Claude 3.5 Sonnet can still generate confident but wrong answers, especially for queries near or past its April 2024 knowledge cutoff. The model sometimes makes up recent events, misstates framework updates, or cites non-existent sources when asked about unfamiliar topics. Always verify time-sensitive information and add citation-checking steps in production pipelines where accuracy is critical.
Multimodal reasoning, while improved, isn’t flawless. Early tests showed occasional UI issues in generated visualizations—legends overlapping axis labels, for instance. The model sometimes produces overly dense graphics that need prompt refinement. For tasks requiring character-level precision (string manipulation, off-by-one indexing), the model still makes errors. Advanced symbolic math and formal proofs remain weaker than GPT-4o, with a five-point gap on the MATH benchmark. Safety filters sometimes block certain content even in legitimate use cases. Partial autonomy means long-running multi-step workflows often require human oversight at decision points, with 40–54% of tasks completing successfully without intervention.
Final Words
We covered what Claude 3.5 Sonnet is, its 2024 release, core specs (200k‑token context, multimodal), features, benchmarks, comparisons, pricing, use cases, integration tips, and known limits.
This gives teams a clear view of where it fits, what it does better, and the trade-offs to watch.
If you plan to test it, start with structured prompts and monitor long‑context behavior. The claude 3.5 sonnet model looks ready for many production tasks and offers faster, stronger reasoning — a practical step forward.
FAQ
Q: What is the Claude 3.5 Sonnet model?
A: The Claude 3.5 Sonnet model is a general-purpose large language model from Anthropic, released in 2024 as part of the Claude 3 family, offering faster inference, better reasoning, and much longer context for enterprise use.
Q: Why is Claude 3.5 Sonnet better than ChatGPT?
A: The Claude 3.5 Sonnet is often better than ChatGPT for enterprise tasks because it offers longer context windows, faster latency, improved reasoning, and enhanced multimodal handling, though task-specific differences still apply.
Q: Can I use Claude Sonnet 3.5 for free?
A: Claude Sonnet 3.5 is generally accessed via Anthropic’s paid API billed per million tokens; occasional free trials or partner platforms may give limited access, but production use typically requires a paid plan.

{kind=link}