

Is a 132B-parameter model really only “36B” when it runs?
Databricks’ DBRX does exactly that: a decoder-only transformer that activates about 36 billion parameters per token using a fine-grained Mixture-of-Experts (MoE) design.
This intro lays out how top-4 routing across 16 experts, MegaBlocks dropless routing, and a shallow-and-wide 40-layer layout cut inference cost while keeping large-model capacity.
Read on for clear technical specs, routing mechanics, long-context tricks, training setup, and practical trade-offs for deployment and performance.
Core Components of the DBRX Model Architecture

DBRX is a decoder-only transformer built on a fine-grained Mixture-of-Experts design. It’s got 132 billion total parameters, but here’s the trick: only 36 billion are active for any given token during inference. This sparse activation pattern cuts compute costs while keeping model capacity intact. Unlike traditional dense transformers where every parameter processes every token (which gets expensive fast), DBRX only lights up the parts it needs.
The MoE routing system picks 4 experts from a pool of 16 for each token. That creates 1,820 possible expert combinations per layer. Compare that to models like Mixtral and Grok-1, which use 8 experts and select 2 per token. DBRX gives you roughly 65 times more routing configurations, letting the model specialize different expert networks for different input patterns. Better performance on code generation, math reasoning, and long-context retrieval without proportionally scaling inference cost.
DBRX uses a shallow-and-wide configuration with approximately 40 transformer blocks. Fewer than Llama2’s 80 layers or Mixtral’s 56. The core pieces include:
- Rotary position encodings (RoPE) for stable long-context representation
- Gated linear units (GLU) in feedforward networks
- Grouped query attention (GQA) to reduce memory bandwidth and speed up decoding
- GPT-4 tokenizer from the tiktoken library
- Decoder-only attention mechanism processing text left to right
- Block-sparse MoE layers with dropless routing via MegaBlocks
Mixture-of-Experts Routing and Expert Selection in DBRX

The routing mechanism determines which 4 of the 16 available experts process each token. A learned gating network evaluates the token’s hidden representation, assigns routing weights to all experts, then selects the top 4 by score. This fine-grained selection creates substantial routing flexibility compared to coarser MoE designs. Each layer independently routes tokens, so the model can adapt its computation path based on input complexity and domain.
Load balancing across experts matters. You don’t want some experts overused while others sit idle. DBRX’s training includes auxiliary loss terms that encourage balanced expert utilization, ensuring all 16 experts contribute meaningfully during inference. This prevents routing collapse, where a small number of experts handle most tokens and the model effectively becomes smaller than designed. Top-4 routing plus load-balancing losses creates a system where expert assignments stay diverse without requiring manual intervention or fixed routing schedules.
Dropless Routing and MegaBlocks
Traditional MoE implementations assign fixed capacity limits to each expert. Tokens get dropped when an expert’s capacity is exceeded, or batches get padded when capacity is underutilized. MegaBlocks removes both inefficiencies by using variable-shaped sparse blocks and block-sparse matrix operations that adapt to actual token assignments. Instead of forcing tokens into predefined slots, the system dynamically groups routed tokens into contiguous memory blocks and performs grouped matrix multiplications (GroupGEMM) that process all selected tokens without padding overhead. This eliminates token drops entirely and reduces wasted computation, improving throughput by 20–40% in memory-bound regimes. MegaBlocks also integrates with GPU kernel optimizations to fuse operations and minimize memory transfers, further accelerating the routing and expert computation phases.
The practical benefits:
- No loss of information from dropped tokens during high-load conditions
- Reduced memory waste from padding in low-load scenarios
- Faster end to end inference via fused GroupGEMM kernels
- Easier scaling to larger batch sizes without capacity tuning
Parameter Structure and Layer Configuration in DBRX

DBRX distributes its 132 billion parameters across embedding layers, 40 transformer blocks, and output projection layers. Each MoE feedforward layer contains 16 expert networks. During inference, only 4 experts per layer are active, reducing the effective compute to approximately 36 billion parameters per token. This sparse structure lets DBRX maintain the representational capacity of a much larger dense model while keeping inference costs closer to a 36-billion-parameter system.
The shallow-and-wide layer design prioritizes expert diversity over layer depth. Compared to Llama2 (80 layers) and Mixtral (56 layers), DBRX’s 40-layer architecture allows faster forward passes with fewer sequential dependencies. This can reduce latency in latency-sensitive deployments. Each layer uses gated linear units in the feedforward blocks, grouped query attention for efficient memory access, and rotary position encodings to handle long-context inputs without degrading positional information at the 32K token limit.
| Model | Layer Count | Design Emphasis |
|---|---|---|
| DBRX | ~40 | Shallow-and-wide with MoE |
| Mixtral | ~56 | Moderate depth with MoE |
| Llama2 | ~80 | Deep dense architecture |
Long-Context Attention and Token Processing in DBRX

DBRX supports a maximum context length of 32,000 tokens. You can process long documents, extended codebases, and multi-turn conversations without truncation. Rotary position encodings provide the positional signal for each token, maintaining stable attention patterns even at the upper end of the context window. Unlike absolute position embeddings that can degrade beyond training lengths, RoPE encodes position through rotation in the embedding space. It generalizes more reliably to longer sequences and reduces extrapolation errors.
Grouped query attention reduces the memory and compute overhead of long-context processing by sharing key and value projections across multiple query heads. This design lowers the key-value cache size during decoding, which is the dominant memory bottleneck when generating text from long prompts. GQA maintains nearly the same quality as full multi-head attention while cutting memory bandwidth requirements by a factor that scales with the grouping ratio. That makes 32K-token inference feasible on standard GPU configurations.
Long-context performance in DBRX has been validated on benchmarks like HotpotQA-XL and KV-Pairs across context lengths from 2K to 32K tokens. The model maintains stable retrieval accuracy and reasoning coherence even when critical information appears far from the query, a common failure mode for models with weaker positional encodings or insufficient attention span. The benefits of DBRX’s long-context design include:
- Accurate retrieval-augmented generation (RAG) with large document sets
- Support for multi-file code analysis and refactoring tasks
- Stable question-answering over long research papers or technical documentation
- Reduced need for truncation or chunking in production pipelines
- Better performance on conversational agents with extended dialogue history
Training Infrastructure and Compute Design Behind DBRX

DBRX was trained on a dataset of 12 trillion tokens over a three-month period using a cluster of 3,072 NVIDIA H100 GPUs. The GPUs were connected via 3.2 terabits-per-second Infiniband networking, providing the low-latency, high-bandwidth communication required for distributed training at this scale. This infrastructure allowed the team to maintain high GPU utilization across thousands of devices, minimizing idle time during gradient synchronization and data loading phases.
The training stack integrated Apache Spark for large-scale data processing and filtering, Unity Catalog for data governance and lineage tracking, and MLflow for experiment tracking and reproducibility. Model development relied on LLM Foundry for training orchestration, MegaBlocks for efficient MoE routing, Composer for training workflows, and Streaming libraries for high-throughput data pipelines. This combination of open-source and proprietary tooling enabled the team to iterate quickly on data curation, model architecture, and hyperparameter tuning.
Training efficiency was a primary design goal. DBRX achieved roughly 2× better FLOP-efficiency than comparably sized dense models, meaning it reached target quality benchmarks with half the floating-point operations. The full training recipe required approximately 4× less compute than previous-generation MPT models to reach similar quality scores. These efficiency gains came from improvements in data quality, curriculum learning schedules, and MoE routing strategies. Lower training costs and faster iteration cycles during model development.
| Resource | Specification |
|---|---|
| GPU Count | 3,072 NVIDIA H100 |
| Interconnect Bandwidth | 3.2 Tbps Infiniband |
| Training Duration | 3 months |
| Dataset Size | 12 trillion tokens |
Inference Optimization and Serving Performance of DBRX

DBRX inference can reach up to 150 tokens per second per user on Databricks Model Serving infrastructure. The serving stack uses fused kernels that combine multiple operations into single GPU launches, reducing memory round-trips and improving arithmetic intensity. GroupGEMM kernels specifically target MoE layers, efficiently batching matrix multiplications across active experts without padding overhead. These kernel-level improvements are critical in memory-bound regimes, where GPU utilization is limited by memory bandwidth rather than compute throughput.
The model achieves roughly 2× faster inference than LLaMA2-70B and less than 0.4× the latency of a comparably sized dense model in small-batch scenarios. At higher concurrency levels (above 32 concurrent users), DBRX sustains decode throughput improvements of 2–3× versus leading dense 70B models. This comes from the sparse activation pattern that reduces per-token compute. Serving configurations typically use 8-way tensor parallelism to distribute the model across multiple GPUs, balancing communication overhead against per-device memory limits. The minimum recommended hardware for 16-bit precision inference is 4 GPUs with 80 GB of memory each, such as H100 80GB or A100 80GB configurations.
Batching strategies play a key role in maximizing throughput. DBRX’s serving engine implements continuous batching, which aggregates multiple user requests into a single forward pass and streams outputs as they’re generated. This approach keeps GPU utilization high even when individual requests arrive asynchronously, avoiding the idle periods that occur in static batching systems. The combination of continuous batching, fused kernels, and MoE-specific optimizations allows DBRX to serve interactive workloads with low per-token latency while maintaining high aggregate throughput under load.
Precision Formats and Quantization Considerations
DBRX supports 16-bit floating-point (FP16) precision by default, which balances memory footprint and numerical stability across most tasks. 8-bit integer quantization (INT8) can roughly halve serving costs and enable deployment on lower-end GPU classes like A10G, improving geographic flexibility and reducing infrastructure spend. But here’s the catch: default INT8 quantization methods in some inference frameworks have been observed to degrade quality on domain-specific benchmarks, particularly HumanEval for code generation and long-context evaluations. Databricks recommends rigorous quality validation when applying quantization, using benchmark suites that reflect production use cases. Their internal stack applies model-specific quantization calibrations to preserve quality, but teams deploying DBRX with third-party inference engines should measure quality regressions carefully before serving quantized versions in production.
Benchmark Results and Quality Characteristics of DBRX
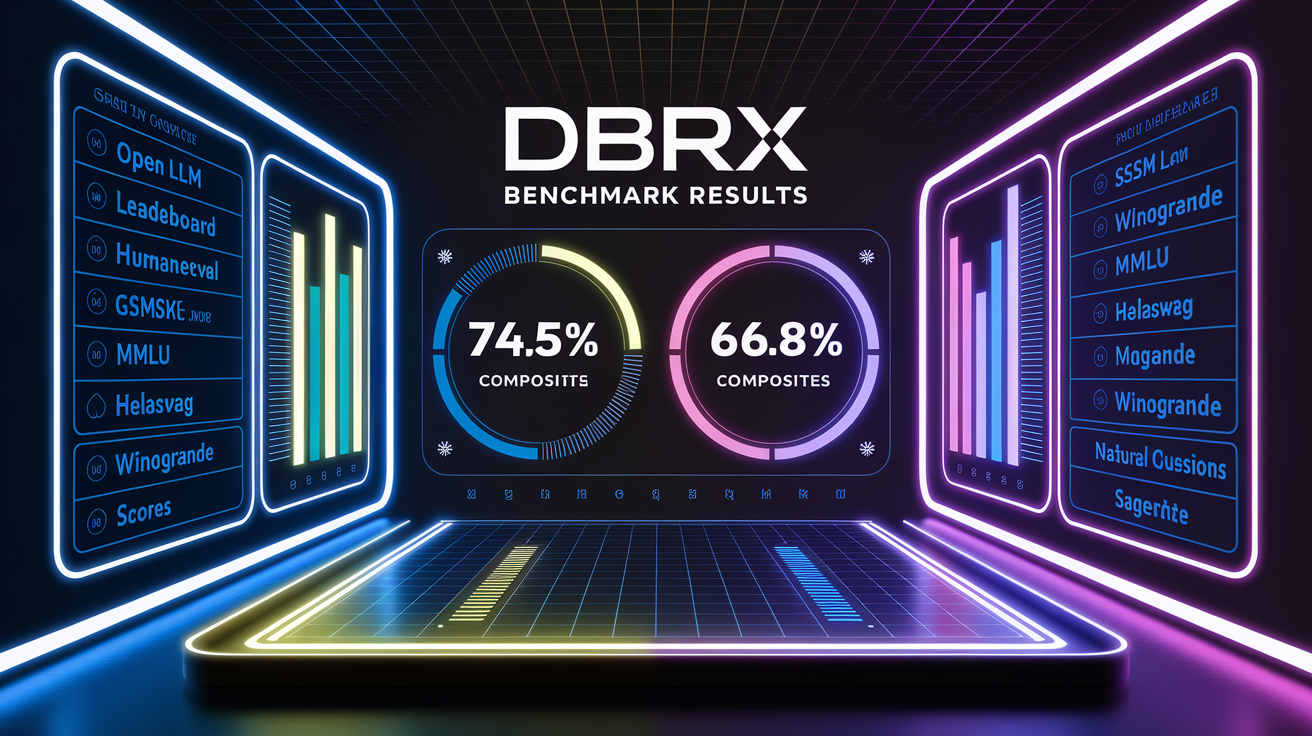
DBRX scores 74.5% on the Hugging Face Open LLM Leaderboard and 66.8% on the Databricks Gauntlet composite benchmark, positioning it above most open models and competitive with several proprietary systems. On programming tasks, the model reaches 70.1% on HumanEval, surpassing CodeLLaMA-70B Instruct at 67.8% and GPT-3.5’s 48.1%. Math reasoning benchmarks show 72.8% on GSM8k with 5-shot prompting, well ahead of GPT-3.5’s 57.1%. General knowledge tasks demonstrate 73.7% on MMLU versus GPT-3.5’s 70.0%.
Across a broader set of evaluation tasks, DBRX achieves 89.0% on HellaSwag and 81.8% on WinoGrande, both standard commonsense reasoning benchmarks. Retrieval-augmented generation quality is measured at 49.3% on Natural Questions, competitive with GPT-3.5 Turbo at 50.9%. Long-context benchmarks like HotpotQA-XL and KV-Pairs confirm stable accuracy across 2K, 4K, 8K, 16K, and 32K token windows.
The model’s benchmark results show consistent advantages over GPT-3.5:
- MMLU (general knowledge): 73.7% vs. 70.0%
- HumanEval (code generation): 70.1% vs. 48.1%
- GSM8k (math reasoning, 5-shot): 72.8% vs. 57.1%
- HellaSwag (commonsense): 89.0% vs. GPT-3.5 baseline
- WinoGrande (coreference): 81.8% vs. GPT-3.5 baseline
- Natural Questions (RAG): 49.3% vs. 50.9% (GPT-3.5 Turbo)
- Databricks Gauntlet: 66.8% (composite across domains)
Comparing DBRX with Other Modern LLM Architectures

DBRX represents approximately 40% of Grok-1’s size in both total and active parameter counts, yet it provides 65 times more expert routing combinations due to its 16-choose-4 design versus Grok-1’s 8-choose-2 configuration. This fine-grained routing increases the model’s ability to specialize across diverse tasks without scaling total parameters proportionally. Compared to Mixtral, which also uses 8 experts selecting 2, DBRX offers significantly more routing flexibility within a similar MoE framework. More nuanced expert assignment and potentially better generalization across domains.
Against GPT-3.5, DBRX shows clear advantages in coding, mathematics, and general knowledge tasks, often by double-digit percentage points. Performance is competitive with Gemini 1.0 Pro and Mistral Medium on several benchmarks, though exact rankings vary by task. The architectural tradeoff is straightforward: DBRX achieves dense-model-level quality with roughly one quarter the active parameters during inference. Lower latency and higher throughput on the same hardware. This efficiency makes DBRX particularly attractive for high-concurrency production workloads where serving cost per token is a key constraint.
| Model | Total Parameters | Active Parameters | Experts (Selected) | Layers |
|---|---|---|---|---|
| DBRX | 132B | 36B | 16 (choose 4) | ~40 |
| Grok-1 | ~330B | ~90B | 8 (choose 2) | N/A |
| Mixtral | ~47B | ~13B | 8 (choose 2) | ~56 |
Customization, Fine-Tuning, and Model Adaptation with DBRX

DBRX is released in two variants: DBRX Base and DBRX Instruct, both available under an open license on Hugging Face. DBRX Base serves as the foundation for custom fine-tuning on domain-specific datasets, while DBRX Instruct is pre-tuned for instruction-following and conversational tasks. Teams can fine-tune either variant using standard supervised learning or reinforcement learning from human feedback (RLHF) workflows, adapting the model to internal terminology, proprietary codebases, or specialized reasoning patterns.
System prompts provide a lightweight customization mechanism without requiring parameter updates. Developers can override default behaviors by injecting task-specific instructions and few-shot examples at the start of each prompt. For instance, a system prompt can configure DBRX to act as a PII detector, a SQL query generator, or a customer-support assistant by providing 3–5 examples that ground the model’s output format and reasoning style. Generation parameters like temperature (range 0 to 1) control output randomness, with lower values suited for deterministic QA and RAG tasks, and higher values enabling creative writing or brainstorming.
Practical recommendations for adapting DBRX:
- Start with simple, explicit instructions before adding complexity or multi-step reasoning
- Use 3–5 few-shot examples to demonstrate the desired output format and style
- Apply consistent delimiters and formatting across all examples to reduce ambiguity
- Encourage step-by-step decomposition or chain-of-thought for complex analytical tasks
- Validate quantized model quality on domain-specific benchmarks before deploying in production
Final Words
We walked through DBRX’s decoder-only Mixture‑of‑Experts core—16 experts, top‑4 routing—and the key blocks that make it run: RoPE, GLU, GQA, grouped query attention, tokenizer, and shallow‑and‑wide layers.
We also covered parameter counts (132B total, 36B active), 32K context handling, the training stack and compute footprint, and serving optimizations like GroupGEMM, fused kernels, and quantization tradeoffs.
If you’re evaluating or adapting models, the databricks dbrx architecture looks like a solid, efficient choice for long‑context workloads. Worth a practical test on your data.
FAQ
Q: What is Databricks DBRX?
A: The Databricks DBRX is a decoder-only transformer with a fine-grained Mixture-of-Experts (16 experts, top-4 routed), 132B total parameters and ~36B active per token, using RoPE, GLU, and GQA.
Q: Is Databricks an Israeli company?
A: Databricks is not an Israeli company; it’s an American cloud-data and AI company headquartered in San Francisco, founded by UC Berkeley researchers and operating globally.
Q: What is the basic architecture of Databricks?
A: The basic architecture of Databricks is a cloud-native data and ML platform built on Apache Spark, combining managed compute (clusters), Delta Lake storage, notebooks, and integrations for governance and APIs.
Q: What is a major weakness for Databricks?
A: A major weakness for Databricks is cost and operational complexity; large workloads can be expensive and require skilled ops for cluster management, governance, and optimizing resource use.

{kind=link}