

What if you could spot a zero-day before it becomes a crisis?
You can’t rely on vendors to issue fixes fast enough.
Threat intelligence—mixing behavioral analytics, dark‑web signals, honeypot data, and automated correlation—lets security teams detect unusual system calls, exploit patterns, and attacker chatter early.
That reduces dwell time, limits damage, and gives defenders time to apply virtual patches or isolate systems while waiting for vendor fixes.
This article shows how intelligence-driven monitoring works, which tools to wire together, and the first practical steps teams should take today.
How Threat Intelligence Enables Zero‑Day Vulnerability Detection and Response

A zero‑day vulnerability is a software or hardware flaw the vendor doesn’t know about yet. Developers literally have zero days to patch before attackers start exploiting it. There’s no official fix when the exploitation begins, so defenders lean on threat intelligence to spot the weird behavior that signals something’s actively being exploited. Threat intelligence supports early detection by pulling together behavioral indicators, anomaly patterns, exploit signatures, and external sources like dark‑web chatter, honeypot logs, and vendor advisories. You’re not waiting around for a CVE number. Security teams use intelligence feeds to catch unexpected system calls, strange file behaviors, or traffic patterns that don’t fit anything you’ve seen before.
Intelligence‑driven detection works by constantly comparing what’s happening now against known‑good baselines and threat‑actor tactics. Behavioral analytics engines flag weird stuff: unusual inter‑process communication, memory‑corruption artifacts, deserialization of untrusted objects. Threat intelligence platforms add external context to these alerts. Maybe similar patterns showed up in recent malware sandboxing reports, or a financially motivated group is known to target that product category. Cross‑source correlation takes network logs, endpoint telemetry, honeypot data, and incident reports from information‑sharing communities and turns isolated anomalies into high‑confidence indicators of zero‑day exploitation.
Once you’ve identified a potential zero‑day, threat intelligence speeds up response by giving you actionable context: which threat actors are probably responsible, what they typically do next, and which compensating controls can shrink the blast radius while a patch gets developed. Intelligence feeds update detection rules in near real‑time, so you can automate containment actions like isolating compromised hosts or blocking command‑and‑control domains. You compress the timeline from initial exploit to mitigation, cutting down the window attackers have to move laterally or steal data.
Core capabilities that threat intelligence delivers for zero‑day detection and response:
- Behavioral anomaly detection – Flags deviations from expected process execution, network traffic, or system‑call patterns.
- Exploit pattern monitoring – Tracks newly observed techniques in wild malware samples and honeypots.
- External intelligence enrichment – Combines internal telemetry with dark‑web monitoring, vendor advisories, and peer‑community reports.
- Automated correlation – Links disparate signals (phishing email, unusual scanning, rare file hash) into a coherent attack narrative.
- Rapid mitigation guidance – Translates technical indicators into actionable workarounds, virtual patches, or network segmentation rules.
Key Threat Intelligence Tools and Platforms for Zero‑Day Monitoring

Threat intelligence platforms pull together indicators of compromise, automate correlation across data sources, and plug into your security infrastructure to surface early signs of exploitation before vendors publish patches. These platforms ingest feeds from commercial vendors, open‑source projects, government agencies, and industry sharing communities, then normalize and enrich the data so analysts can prioritize alerts that actually match their environment. When you wire TIPs into SIEM and SOAR systems, you’re transforming raw intelligence into automated actions: blocking malicious IPs, isolating suspect endpoints, triggering incident‑response playbooks the second a zero‑day indicator appears.
Modern zero‑day monitoring relies on a layered toolset. Threat intelligence platforms for aggregation and context. SIEM solutions for centralized log analysis. SOAR for orchestration and automated response. Endpoint detection and response tools for real‑time telemetry from workstations and servers. Each category plays a distinct role: TIPs provide the “what’s happening globally” view, SIEM correlates that view with internal activity, SOAR executes predefined countermeasures, and EDR delivers the granular host‑level data you need to confirm exploitation attempts. Together, these tools shorten mean‑time‑to‑detect and mean‑time‑to‑contain for zero‑day events.
| Tool Category | Primary Function | Zero‑Day Role |
|---|---|---|
| Threat Intelligence Platforms (TIP) | Aggregate and enrich indicators from multiple feeds | Correlate external zero‑day signals (dark‑web chatter, honeypot hits) with internal telemetry |
| Security Information and Event Management (SIEM) | Centralize and analyze logs from network, endpoint, and application sources | Detect anomalies and unusual traffic patterns consistent with zero‑day exploitation |
| Security Orchestration, Automation and Response (SOAR) | Automate incident workflows and containment actions | Execute rapid isolation, IP blocking, and alert escalation when zero‑day indicators match environment |
| Endpoint Detection and Response (EDR) | Monitor host‑level activity and provide forensic telemetry | Capture memory‑corruption artifacts, unexpected system calls, and behavioral anomalies at the endpoint |
Methodologies for Detecting and Tracking Zero‑Day Exploits

Detecting zero‑day exploits requires methods that can identify malicious activity without relying on known signatures or CVE identifiers. Heuristic analysis evaluates code behavior against a set of rules derived from common exploit patterns: memory corruption, unexpected privilege escalation, abnormal network connections initiated by low‑level system processes. Anomaly‑based detection establishes baselines for normal system and network behavior, then flags deviations. Unusual inter‑process communication, rare file writes to system directories, or unexpected GPU calls that might indicate a sandbox‑escape attempt. These methods surface suspicious activity even when the underlying vulnerability has never been publicly disclosed.
Active exploit scanning and sandboxing add another layer on top of passive monitoring. You’re proactively testing suspicious files and network traffic in isolated environments. Malware sandboxes execute unknown binaries and observe their actions, watching for code injection, registry modifications, or attempts to escalate privileges. Network telemetry analysis examines packet headers, payloads, and traffic timing to detect exfiltration patterns or command‑and‑control beaconing that comes before or after zero‑day exploitation. By stacking multiple detection layers, security teams increase the chances of catching zero‑day activity before attackers get what they came for.
Tracking zero‑day exploits means continuously correlating internal telemetry with external intelligence sources. This lets analysts follow an attack from initial access through lateral movement and data exfiltration. The workflow below describes a typical tracking process that starts with anomaly detection and ends with validated mitigation.
Typical zero‑day tracking workflow:
- Ingest and correlate telemetry – Collect logs from endpoints, network devices, and cloud services. Enrich with threat‑intelligence feeds.
- Flag anomalies – Use behavioral analytics and heuristic rules to identify unusual system calls, memory access, or network activity.
- Validate and triage – Isolate suspect systems. Perform memory forensics and sandbox analysis to confirm exploit behavior.
- Map to threat actors – Compare observed tactics, techniques, and procedures against known adversary profiles and recent campaign reports.
- Develop containment actions – Implement virtual patches, network segmentation, or service isolation while waiting for vendor remediation.
- Update detection rules – Feed validated indicators back into SIEM, EDR, and firewall rulesets to block future attempts and share findings with intelligence‑sharing communities.
Intelligence Sharing Channels That Accelerate Zero‑Day Awareness

Intelligence sharing communities like Information Sharing and Analysis Centers and Computer Emergency Response Teams distribute early warnings, exploit proofs‑of‑concept, and cross‑sector insights that help organizations detect and respond to zero‑day threats faster than any single entity could alone. ISACs operate within specific industries (financial services, healthcare, energy, telecommunications) and provide members with curated alerts about emerging threats, including zero‑days targeting sector‑specific software or infrastructure. CERTs coordinate across national and international boundaries, publishing advisories and technical analysis that security teams use to prioritize patching and implement compensating controls before widespread exploitation happens.
Shared intelligence shrinks the time between initial exploitation and collective defense. When one organization detects a zero‑day, sharing indicators of compromise, behavioral signatures, and mitigation guidance lets hundreds or thousands of peers update detection rules and block the same attack vector within hours instead of days or weeks. This multiplier effect matters especially for zero‑days, where the absence of a vendor patch means defensive measures have to be improvised quickly. Intelligence‑sharing platforms like MITRE ATT&CK, Open Threat Exchange, and sector‑specific portals provide structured formats and automation‑friendly feeds that plug directly into SIEM and SOAR tools.
Beyond technical indicators, intelligence sharing includes context about threat‑actor attribution, campaign timelines, and targeted industries. Knowing that a PRC‑nexus espionage group is actively exploiting edge devices or that a financially motivated cluster is using a specific exploit chain helps security teams prioritize which zero‑days pose the highest risk to their environment. Participating in these communities also creates informal channels for real‑time collaboration during active incidents, so you get faster triage and coordinated disclosure that cuts down attacker advantage.
Threat Actor Profiling for Predicting Zero‑Day Exploitation Patterns

Advanced persistent threat groups, commercial surveillance vendors, and financially motivated clusters use zero‑day vulnerabilities as a primary means of initial access. Profiling these actors helps security teams anticipate which products, sectors, and techniques are most likely to be targeted next. Threat actor profiling combines historical campaign data, known tactics and procedures, and infrastructure analysis to build a picture of each group’s capabilities, preferred targets, and operational tempo. For example, PRC‑nexus espionage groups have consistently targeted edge appliances (firewalls, VPNs, security gateways), while commercial surveillance vendors focus on mobile operating systems and messaging applications to enable targeted surveillance.
Profiling also reveals patterns in exploit chaining and post‑exploitation behavior. Some actors routinely combine renderer vulnerabilities with kernel or GPU driver flaws to achieve full device compromise. Others specialize in exploiting single high‑value vulnerabilities in enterprise software. Understanding these patterns lets defenders prioritize hardening measures, like disabling unnecessary services on edge devices or enforcing strict driver block lists, that shrink the attack surface for the tactics most likely to be used against them.
You can map threat‑actor preferences to your organization’s technology stack and business profile, then allocate monitoring and mitigation resources where they’ll have the greatest impact. If a financially motivated group is known to target Oracle EBS deployments and you run that software, you elevate monitoring for the CVEs and behavioral indicators tied to that actor’s campaigns. This risk‑based approach turns zero‑day threat intelligence into concrete defensive actions instead of an overwhelming list of theoretical vulnerabilities.
Integrating Zero‑Day Threat Intelligence Into SOC Operations

Integrating zero‑day threat intelligence into security operations centers enables automated alerting, refined detection rules, rapid triage, and incident prioritization for exploitation attempts. Threat intelligence platforms feed curated indicators (file hashes, network signatures, behavioral patterns, and threat‑actor TTPs) directly into SIEM and SOAR systems, where they’re correlated with live telemetry from endpoints, network devices, and cloud infrastructure. When a TIP identifies a new zero‑day indicator, the SIEM automatically updates correlation rules and the SOAR platform kicks off predefined playbooks: isolating affected systems or blocking suspect IP ranges without requiring manual analyst intervention.
Operationalizing intelligence requires SOCs to maintain an accurate, real‑time inventory of internet‑facing assets and internal services, tagged by business criticality and technology stack. When a zero‑day targeting Fortinet firewalls or Cisco VPNs gets disclosed, the SOC can immediately tell which assets are affected, who owns them, and what the potential blast radius looks like. This asset‑intelligence mapping lets analysts prioritize alerts based on actual risk rather than treating every vulnerability equally. Pre‑approved emergency actions (temporarily restricting administrative access, forcing VPN upgrades, disabling vulnerable services) can be executed within minutes instead of waiting for change‑management approval during an active exploitation event.
Continuous feedback loops between threat intelligence and SOC workflows improve detection accuracy over time. Analysts validate alerts, enrich them with additional context from memory forensics or sandbox analysis, and feed confirmed indicators back into the TIP. This closed‑loop process cuts down false positives and tunes detection rules to focus on the handful of zero‑days that actually match your environment and threat profile.
SOC workflows updated with zero‑day indicators:
- Automated enrichment – Alerts are tagged with threat‑actor attribution, campaign context, and mitigation recommendations from the TIP.
- Dynamic detection rules – SIEM correlation rules are updated in real time when new zero‑day indicators appear in intelligence feeds.
- Playbook‑driven response – SOAR executes containment actions (isolate host, block IP, disable service) based on predefined triggers for high‑confidence zero‑day matches.
- Escalation and communication – Incidents are automatically routed to the correct response team, and executive summaries are generated for leadership within the first 24 hours.
Response and Mitigation Workflows for Zero‑Day Events
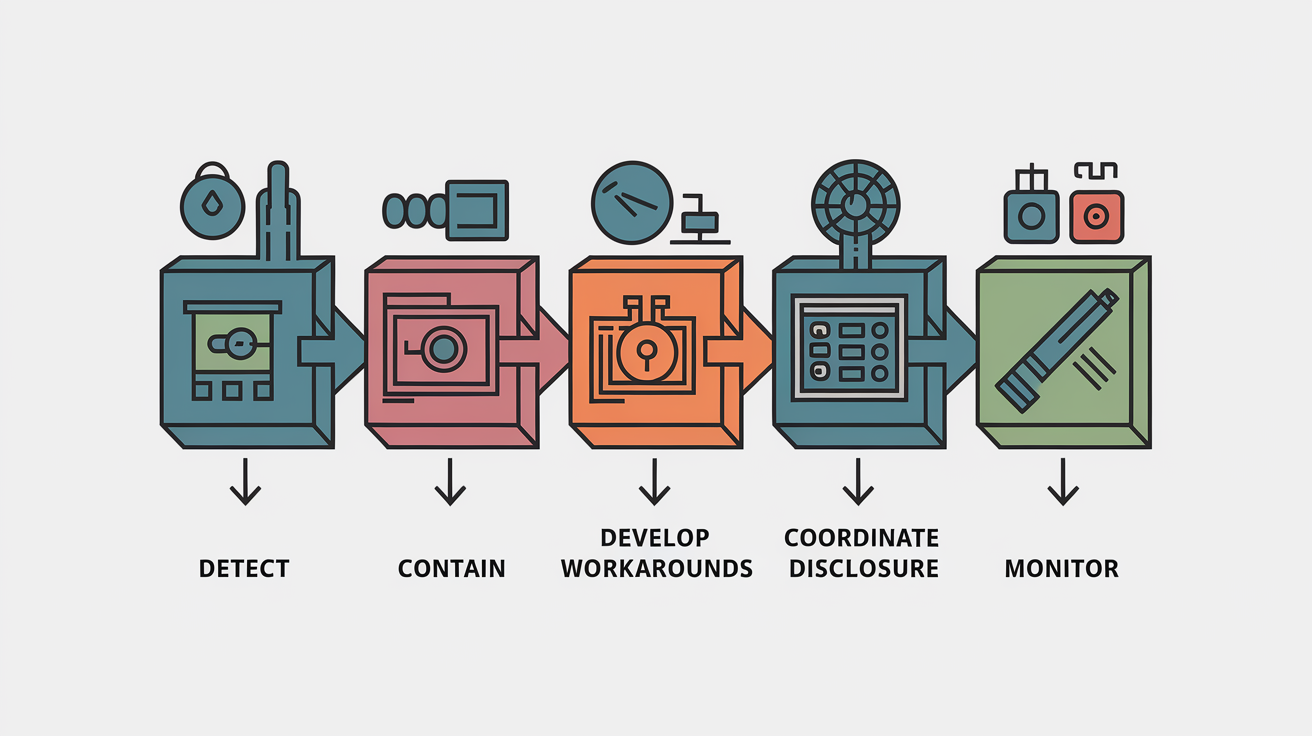
Effective zero‑day mitigation starts the moment a high‑confidence indicator is detected and follows a structured workflow: containment, analysis, temporary workarounds, vendor coordination, and continuous monitoring. First priority is isolating affected systems to prevent lateral movement. This might mean disabling network interfaces, blocking traffic at the firewall, or placing endpoints into a restricted VLAN. Isolation has to be surgical. Security teams need to keep visibility for forensic collection while cutting off the attacker’s ability to pivot to other assets or steal data.
At the same time, analysts reverse‑engineer the exploit to understand the attack vector, affected components, and post‑exploitation behavior. This analysis informs the development of virtual patches or compensating controls that reduce risk while you’re waiting for an official vendor fix. Virtual patching can take the form of web application firewall rules that block specific HTTP patterns, endpoint detection signatures that kill malicious processes, or network rules that prevent vulnerable services from communicating with external networks. Rapid communication with vendors and national authorities like CISA means intelligence about the zero‑day is shared widely and patch development gets prioritized.
Post‑incident, security teams update policies, hardening controls, and detection rules based on lessons learned. If the zero‑day exploited a deserialization flaw, organizations might implement signature checks on serialized objects or disable deserialization on internet‑facing services. Continuous monitoring for indicators of compromise and behavioral anomalies stays in place even after a patch is deployed, because attackers often maintain persistence through backdoors or alternate access methods they established during the initial compromise.
Zero‑day response workflow stages:
- Detect and validate – Correlate anomaly alerts with threat intelligence. Confirm exploitation through sandbox or memory forensics.
- Contain and isolate – Disconnect affected systems from the network or restrict them to a monitored segment. Preserve forensic evidence.
- Develop and deploy workarounds – Implement virtual patches, disable vulnerable services, apply network‑level mitigations while waiting for vendor patch.
- Coordinate disclosure and patching – Notify vendors, information‑sharing communities, and regulatory authorities. Prioritize emergency patch deployment when available.
- Update defenses and monitor – Integrate new indicators into SIEM/EDR. Tune detection rules. Conduct threat hunting to confirm no additional persistence mechanisms remain.
Real‑World Zero‑Day Case Studies and Lessons Learned

The Stuxnet worm, discovered in 2010, used four zero‑day vulnerabilities to infiltrate and sabotage Iranian nuclear centrifuges. It showed how chained zero‑days can achieve strategic objectives way beyond traditional espionage or financial theft. Stuxnet exploited flaws in Windows print spooler services, task scheduler, and USB autorun to spread across air‑gapped industrial networks, then used a Siemens STEP 7 vulnerability to alter programmable logic controller code without detection. The campaign proved that zero‑days targeting operational technology can have physical consequences and highlighted the importance of network segmentation, strict device access controls, and behavioral monitoring in environments where traditional endpoint security is limited. Intelligence sharing after Stuxnet’s discovery sped up detection of similar techniques in later campaigns and led to broader adoption of threat‑hunting practices in critical infrastructure sectors.
A more recent example involves a PRC‑nexus advanced persistent threat group exploiting a zero‑day in enterprise VPN gateways to gain initial access to government and defense networks. The vulnerability allowed unauthenticated remote code execution on internet‑facing appliances, and the attackers used it to install web shells and establish persistent backdoors before the vendor released a patch. Threat intelligence from CERTs and ISACs provided early indicators of exploitation, including specific HTTP request patterns and file paths tied to the web shells. This let organizations detect compromises and isolate affected gateways within hours of the public advisory. Post‑incident analysis showed that many affected organizations lacked accurate inventories of edge devices, which delayed their ability to map the zero‑day to actual assets.
Both cases point to the value of maintaining real‑time asset inventories, deploying behavioral detection on edge and OT devices, and participating in intelligence‑sharing communities. Organizations that had integrated threat intelligence into their SOC workflows and pre‑authorized emergency containment actions were able to mitigate the zero‑days before significant damage occurred. Those relying solely on vendor notifications faced longer exposure windows and higher remediation costs.
Final Words
We showed how threat intelligence turns early signals into faster detection and response for zero‑day flaws, covering feeds and platforms, detection methods, sharing channels, actor profiling, SOC integration, response workflows, and case studies.
That matters: intelligence helps prioritize alerts, tune defenses, coordinate teams, and apply temporary controls while vendors patch.
Start by integrating zero day vulnerability threat intelligence into monitoring and playbooks. Small steps now cut exposure and make your team more ready — and that’s a positive place to be.
FAQ
Q: What is a zero-day vulnerability attack?
A: A zero-day vulnerability attack is an exploit that targets a software flaw vendors don’t yet know about or haven’t patched, letting attackers breach systems before a fix is available.
Q: What are the 3 C’s of cybersecurity?
A: The 3 C’s of cybersecurity are confidentiality, integrity, and availability, meaning protect data privacy, ensure accuracy and trustworthiness, and keep systems and services accessible.
Q: What are the 4 types of vulnerabilities?
A: The four types of vulnerabilities are software (bugs or coding errors), hardware (device flaws), network (protocol or configuration weaknesses), and human (social engineering or misconfigurations).
Q: What are the four types of threat intelligence?
A: The four types of threat intelligence are strategic, operational, tactical, and technical—ranging from high-level trends to campaign motives, attacker tactics, and specific indicators like IPs or hashes.

{kind=link}