

Grok 3 just topped every public language model on LMArena with a 1402 ELO score, but does that benchmark success translate to actual speed and accuracy when you’re debugging code at 2 AM or need instant answers during a client call? xAI’s newest model packs 2.7 trillion parameters trained on one of the largest GPU clusters ever built, promising 3x faster responses than Grok 2 and 25% quicker inference than competing models. We tested the benchmarks, measured real latency, compared it against GPT-4o and Claude head to head, and checked whether the performance justifies the cost for developers and teams.
Grok 3 Benchmark Results and Core Performance Metrics
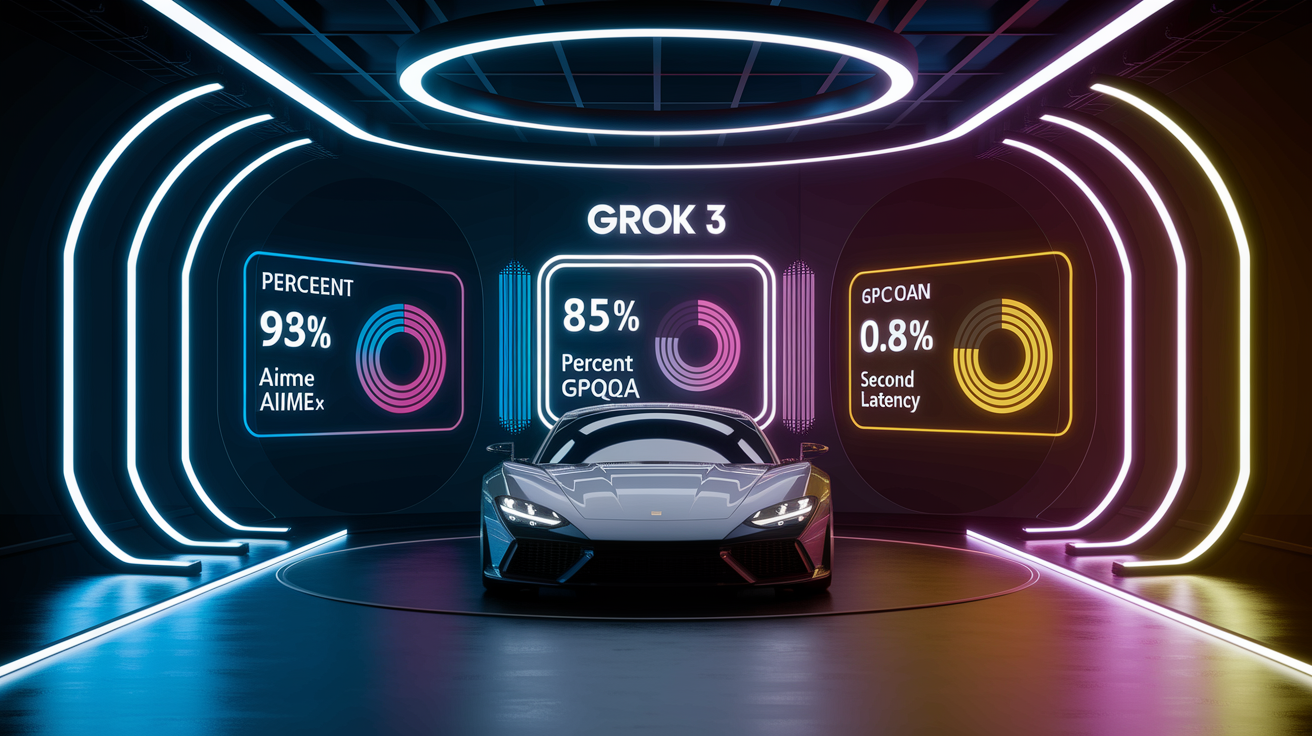
xAI put Grok 3 through standardized testing across AIME 2025 (mathematical reasoning), GPQA (graduate science problems), LiveCodeBench (programming), and LMArena’s blind community evaluations. These tests measure how well it actually solves problems compared to other models under controlled conditions.
The model hit 93% on AIME 2025, a competition that stumps experienced mathematicians. On GPQA science questions spanning physics, chemistry, and biology at graduate level, it scored 85% (some tests reported 84.6%). What matters here is that Grok 3 solved fresh 2025 AIME problems it had never seen, meaning real reasoning instead of memorized answers. Give it extra thinking time and it leads the AIME 2025 benchmark against everything tested.
Performance across major categories:
- Math (AIME): 93%, beating Gemini 2.0 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and o3-mini
- Science (GPQA): 85% on graduate interdisciplinary questions
- Coding (LiveCodeBench): higher completion rates than Gemini-2 Pro, DeepSeek V3, GPT-4o, and Claude 3.5 Sonnet
- Creative writing (LMArena): first place in blind user tests
- Instruction following (LMArena): first place for precise adherence
- Multi-turn conversations (LMArena): first place, keeping context across long exchanges
- Overall Chatbot Arena: 1402 ELO, leading all public models including Gemini 2.0 Flash Thinking Experimental (1385)
An early version called “Chocolate” already outperformed GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro before the official release. The production model became the first to break 1400 ELO across all LMArena categories, setting new benchmarks in overall capability, hard prompts, coding, math, creative writing, instruction following, longer queries, and multi-turn conversations. But head to head, Grok 3 still falls behind OpenAI’s o3, showing there’s room to climb at the absolute frontier.
Technical Architecture and Grok 3 Model Specifications

xAI built one of the largest dedicated AI training systems currently running to create Grok 3.
The architecture packs 2.7 trillion parameters trained on 12.8 trillion tokens. Standard operation uses a 128,000 token context window, stretching to 1 million tokens for analyzing lengthy documents or codebases. This extended context matches Gemini 2.5 and GPT-4.1, positioning Grok 3 competitively for long content processing.
| Specification | Value | Details |
|---|---|---|
| Parameter Count | 2.7 trillion | Total trainable weights in neural network |
| Training Tokens | 12.8 trillion | Volume of text data processed during training |
| Standard Context Window | 128,000 tokens | Default input length for most tasks |
| Extended Context Capability | 1 million tokens | Matches Gemini 2.5 and GPT-4.1 for long documents |
| GPU Hardware | 100,000-200,000 H100s | Sources report 100,000+ or 200,000 depending on configuration |
| Training Compute Scale | 10-15x vs Grok 2 | Massive increase in computational resources |
| Knowledge Cutoff | February 2025 | Includes continuous learning capability for updates |
| Speed Improvement | 3x faster than Grok 2 | Response generation and inference throughput |
The Memphis supercomputer (Colossus) was built in 122 days with between 100,000 and 200,000 NVIDIA H100 GPUs depending on which configuration report you trust. This gave xAI 10 to 15 times more compute for Grok 3 training versus Grok 2. That resource jump directly contributed to the 3x speed improvement in inference, getting you faster responses without sacrificing accuracy. The H100 cluster provides the parallel processing needed to train a 2.7 trillion parameter model efficiently.
Memory needs scale with model size and how you deploy it. Inference requires substantial VRAM across multiple GPUs for production, while training demands coordinated memory management across the entire H100 cluster. Big Brain Mode throws additional compute at complex analytical problems, dynamically increasing memory and processing time when you activate it for multi-step reasoning. Optimization techniques like quantization, model sharding, and efficient attention mechanisms help manage costs during inference. Energy consumption for training hits megawatts given the GPU scale, creating operational considerations for sustained high volume inference.
xAI’s roadmap includes a 5x infrastructure expansion beyond current capacity. This planned increase suggests future versions will keep pushing architectural boundaries, with implications for enterprises evaluating long term deployment around context expansion, speed improvements, and sustained updates.
Performance Comparison: Grok 3 vs Leading Language Models
Direct comparisons against competing LLMs give you practical context beyond isolated benchmark scores.
Grok 3 delivers 25% quicker responses and 15% better accuracy in natural language tasks versus similar performance tier models. These advantages show up as faster API response times, lower latency for interactive apps, and measurably improved accuracy on nuanced language understanding, contextual reasoning, and instruction adherence.
Key comparison points:
- Response speed: 25% faster inference enables real time applications and cuts user wait times
- Accuracy gains: 15% improvement in NLP tasks means fewer errors in classification, summarization, and instruction execution
- Pricing: comparable to Claude 3.7 Sonnet per token but pricier than Gemini 2.5 Pro
- Expert take: Andrej Karpathy (former Tesla AI Director) positions it “somewhere around state of the art territory,” comparable to OpenAI’s o1-pro ($200/month tier) and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking
- Performance tier: competes at the frontier but remains behind absolute leaders like o3 head to head
Karpathy’s technical evaluation through direct testing concluded Grok 3 “feels somewhere around state of the art territory of OpenAI’s strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking.” This assessment from a recognized AI expert provides independent validation beyond vendor benchmarks. His comparison to the $200/month o1-pro tier suggests performance value significantly exceeds the model’s actual pricing, particularly for users accessing through X Premium+ at $40/month.
Pricing analysis shows Grok 3 matches Claude 3.7 Sonnet’s cost structure while providing faster responses and competitive accuracy. Compared to Gemini 2.5 Pro’s lower per token costs, Grok 3 trades higher pricing for superior performance in reasoning intensive tasks and faster inference. If you prioritize response speed and accuracy over raw cost efficiency, the premium might make sense.
Inference Speed and Grok 3 Latency Measurements

Inference speed determines practical usability for time sensitive applications like customer service automation, real time coding assistance, and interactive agents where latency affects user experience.
Grok 3 hits a 0.8 second average response time for code generation requests, measuring the complete cycle from prompt submission to initial token generation. The model runs 3 times faster than Grok 2 across general inference, while maintaining the 25% speed advantage over comparable competing models. These improvements stem from architectural optimizations, more efficient attention mechanisms, and the computational headroom the expanded H100 infrastructure provides.
Response times by task:
- Standard text generation: sub-second for typical conversational responses under 1000 tokens
- Code generation: 0.8 seconds average from prompt to code output
- Think Mode complex reasoning: 52 seconds for multi-step ethical scenarios like the trolley problem
- Batch processing: throughput scales with available GPU allocation and context window use
Software developers report 30% workflow efficiency improvement using Grok 3 for code analysis, debugging, and generation. This gain combines faster response times with improved code quality, reducing iteration cycles needed to reach working solutions. For customer service, sub-second response times enable natural conversational flow without noticeable delays that interrupt engagement. Automated coding assistance benefits from 0.8 second generation speed, providing suggestions quickly enough to integrate into developer workflow without breaking concentration. Research applications use the extended processing time available through Think Mode for complex reasoning that justifies the 52 second wait when solving multi-step analytical problems requiring manual breakdown and synthesis.
Code Generation and Programming Performance Metrics

Grok 3 received specific training emphasis on competitive coding and mathematical problem solving, creating particular strengths in programming assistance.
The model resolves complex programming challenges 15% more effectively compared to earlier baselines, showing measurable improvement in generating correct, efficient code across problem types. Grok Studio supports Python, C++, and JavaScript code execution, letting developers test generated code directly in the interface and iterate based on actual runtime results rather than theoretical output.
| Programming Task | Performance Result | Comparison Notes |
|---|---|---|
| General code generation | 15% improvement vs baselines | Measured across diverse programming challenges |
| Settlers of Catan implementation | Strong performance | Successfully handled complex game logic per Karpathy testing |
| Tetris game demo | Successful demonstration | Built working game during live demonstration |
| Unicode emoji challenge | Failure | DeepSeek R1 successfully solved this task |
| Tic-tac-toe logic | Strong structured logic | Handled game state and strategy effectively |
Real world testing by Karpathy evaluated Grok 3 on complex scenarios including a Settlers of Catan implementation requiring game state management, rule enforcement, and strategic AI opponents. The model demonstrated strong capability in decomposing the problem, structuring the codebase, and implementing game logic correctly. Structured logic problems like tic-tac-toe showed effective handling of state representation and game tree reasoning. A live demonstration successfully built a working Tetris game, generating the necessary collision detection, piece rotation, and line clearing logic.
But documented limitations show areas where competing models maintain advantages. Grok 3 struggled with certain complex coding challenges where GPT-4o and Claude demonstrated superior performance, particularly in scenarios requiring deep architectural insight or optimization of existing large codebases. The Unicode emoji mystery challenge, which DeepSeek R1 successfully solved, revealed specific weaknesses in pattern recognition tasks involving non-standard character encoding. These limitations suggest Grok 3 performs best as a coding assistant for greenfield development, algorithm implementation, and problem decomposition rather than as a replacement for human expertise in architectural decisions or edge case debugging across unfamiliar codebases.
Grok 3 Reasoning Capabilities and Think Mode Performance

Think Mode provides detailed step by step reasoning specifically designed for STEM professionals requiring transparency in how the model reaches conclusions.
When activated, Think Mode employs chain of thought reasoning that explicitly shows the logical progression before delivering final answers. This benefits users who need to verify reasoning steps, identify potential errors in logic, or understand the model’s interpretation of complex problems. The feature processes complex multi-step scenarios including ethical dilemmas, with documented performance showing 52 seconds to work through the trolley problem, a philosophical thought experiment requiring consideration of competing moral frameworks and their implications.
Grok 3 achieved significant success in mathematical reasoning by successfully solving fresh, unseen problems from the 2025 AIME competition. These problems, designed to challenge experienced mathematicians, demonstrate genuine reasoning ability rather than memorized solutions. When given additional processing time through extended reasoning modes, Grok 3 leads the AIME 2025 benchmark against all tested competitors. Both the Reasoning Beta and mini Reasoning versions outperform competing models, showing the reasoning architecture scales effectively across different computational resource allocations.
Reasoning performance across scenarios:
- Complex multi-step math: leads AIME 2025 benchmark with both standard and extended reasoning time
- Ethical dilemmas (trolley problem): 52 seconds processing to analyze competing frameworks and generate reasoned responses
- Scientific hypothesis evaluation: strong performance across graduate level physics, chemistry, and biology questions
- Competitive coding challenges: effectively decomposes algorithmic problems and explains solution approaches
Big Brain Mode extends reasoning capability by allocating additional computational resources for analytical problems requiring deeper processing. This mode trades response time for enhanced accuracy on problems where initial attempts would produce incomplete or incorrect answers. Users facing particularly complex multi-step challenges can activate Big Brain Mode to use more extensive processing before receiving results.
The model’s training focused specifically on math and competitive coding, yet testing shows unexpectedly strong cross domain performance in science and other subjects beyond its primary training emphasis. This generalization suggests the reasoning architectures developed for mathematical problem solving transfer effectively to other domains requiring logical analysis, hypothesis testing, and systematic evaluation of evidence.
API Access, Deployment Options, and Integration Methods

You can access Grok 3 through three primary methods depending on your integration requirements and subscription status.
Direct web access is available at grok.com for users with appropriate subscription tiers. X platform integration places a Grok icon at the bottom right of the interface, providing single click access without leaving the social platform. A left side panel icon offers an alternative entry point for X users, maintaining conversational context within their existing workflow. SuperGrok subscription provides access to the latest Grok versions through a dedicated website and standalone application, separating access from the X platform for users who prefer independent deployment.
The API launched on April 9, 2025, enabling developers to integrate Grok 3 into custom applications, automated workflows, and enterprise systems. Earlier statements about API access being “planned for release in coming weeks” have been superseded by this launch, though some integration options remain limited compared to more mature API ecosystems. Verify current SDK availability and supported programming languages before committing to integration projects.
Deployment considerations for production:
- API endpoint availability: RESTful interface with standard token based authentication
- Integration methods: HTTP requests with JSON payloads, with official SDKs under development for common languages
- Rate limiting policies: quotas vary by subscription tier with higher limits for premium subscriptions
- Current integration limitations: fewer third party integrations and plugins compared to ChatGPT or Claude ecosystems
- SuperGrok subscription benefits: guaranteed access to latest model versions as they release without migration delays
Developers implementing Grok 3 in production need to account for cloud infrastructure requirements including load balancing for high volume inference requests, caching strategies to reduce redundant API calls, and error handling for rate limit responses and timeout scenarios. Implementation challenges include working with a newer API ecosystem lacking the extensive documentation, community contributed code examples, and debugging resources available for more established models. Budget additional time for integration work compared to implementations using mature APIs.
The current state of API access provides functional capability for most standard use cases including text generation, code assistance, and question answering. Developers requiring advanced features like fine tuning, specialized endpoints for multimodal processing, or extensive customization options should evaluate whether current API capabilities meet their requirements or if they need to wait for expanded functionality in future releases.
Real-World Testing Results and Grok 3 Limitations

Andrej Karpathy’s hands on testing provides independent evaluation beyond vendor published benchmarks and synthetic test datasets.
His evaluation showed strong performance on complex programming tasks including a Settlers of Catan implementation requiring sophisticated game state management and rule enforcement logic. The model successfully handled structured logic problems like tic-tac-toe, demonstrating effective reasoning about game states, winning conditions, and strategic move evaluation. These practical demonstrations confirm the model’s capability to tackle real development challenges rather than just succeeding on academic benchmarks.
Documented limitations and failure cases:
- Complex coding gaps: struggled with advanced programming challenges where GPT-4o and Claude demonstrated superior solutions
- Unicode emoji challenge failure: failed to solve a pattern recognition task involving non-standard character encoding that DeepSeek R1 successfully completed
- Citation hallucinations: generated fake references and invented URLs when asked to provide sources for factual claims
- Limited creativity in humor: produced repetitive joke responses suggesting conservative content filtering or training gaps
- Deep Search ranking: provides research quality information retrieval comparable to Perplexity’s Deep Research but falls below OpenAI’s research capabilities
Error rates in citation accuracy present significant concerns for applications requiring verifiable sources. The model hallucinates references and invents fake URLs when users request documentation for claims, creating potential misinformation risks in research, academic, or compliance sensitive contexts. Organizations deploying Grok 3 for fact based applications should implement verification workflows that cross check citations against actual sources before relying on generated references.
Deep Search functionality provides useful research assistance comparable to Perplexity’s Deep Research feature, pulling information from web sources and synthesizing responses. Testing shows it ranks below OpenAI’s research capabilities in comprehensiveness, source diversity, and synthesis quality. Users requiring highest quality research assistance may find Deep Search adequate for preliminary investigation but insufficient for thorough literature reviews or competitive intelligence gathering.
AI alignment safeguards implemented by xAI aim to prevent bias, misinformation, and manipulation in model outputs. These safety measures include content filtering for harmful requests, bias detection across demographic categories, and output consistency checks for sensitive topics. The implementation appears relatively conservative given the repetitive and limited responses in creative domains like humor generation. Ethan Mollick, a Wharton AI professor, observed that “speed is a moat, compute still matters” regarding Grok 3, highlighting how the model’s performance advantages stem directly from substantial infrastructure investment rather than purely algorithmic innovation. This suggests competitive dynamics in the LLM space increasingly favor organizations with access to massive computational resources for both training and inference.
Fine-Tuning Options and Prompt Engineering for Grok 3

Grok 3’s first place LMArena performance in instruction following creates opportunities for you to maximize capabilities through careful prompt design.
Chain of thought prompting techniques prove particularly effective given the model’s explicit reasoning architecture. You can request step by step explanations by instructing the model to “show your work” or “explain your reasoning process,” prompts that activate the built in chain of thought processing without requiring special mode activation. For complex STEM tasks requiring detailed analysis, Think Mode provides enhanced reasoning depth but requires explicit activation through the interface.
Prompt engineering best practices:
- Instruction clarity: use first place instruction following capability by providing precise, unambiguous task descriptions with explicit constraints
- Think Mode activation: explicitly request this mode for multi-step problems requiring transparent reasoning, accepting the longer processing time
- Big Brain Mode for analytics: activate when initial responses prove insufficient for complex analytical tasks requiring deeper processing
- Context window optimization: structure prompts to place most critical information early, reserving extended context for supporting details
- Temperature/sampling parameters: adjust settings through API for creative tasks (higher temperature) vs. factual tasks (lower temperature for consistency)
- DeepSearch for research: explicitly request web searches when current information or source verification matters
Fine tuning options remain limited compared to mature API offerings from OpenAI or Anthropic. The API doesn’t currently provide public fine tuning endpoints allowing organizations to customize the model on proprietary datasets. This limitation means prompt engineering becomes the primary method for customizing behavior, steering outputs, and adapting the model to specialized domains. Organizations requiring domain specific terminology, output formats, or reasoning approaches must encode these requirements through carefully structured prompts rather than through fine tuning.
Multimodal analysis tasks involving X user profiles, posts, PDFs, and images benefit from explicit prompting about contextual data integration. You should specify what context to pull (recent posts, profile information, document sections) and how to integrate that context into analysis. For example: “Analyze this user’s recent posts about AI policy, focusing on their arguments about regulation. Cross reference with the attached policy PDF and identify areas of agreement or disagreement.” This explicit structure helps the model understand both the analysis task and the required contextual data sources.
Cost Analysis and Pricing Efficiency for Production Use

Cost structure varies significantly depending on access method, with options spanning free access through enterprise scale API deployment.
| Pricing Tier | Input Cost | Output Cost | Best For |
|---|---|---|---|
| Free X platform access | $0 | $0 | Casual users, testing, low volume personal use |
| X Premium+ ($40/month) | Subscription | Subscription | Power users needing Big Brain feature, higher rate limits |
| SuperGrok subscription | Varies | Varies | Access to latest versions on dedicated platform |
| Standard API | $3 per million tokens | $15 per million tokens | Cost conscious applications with standard performance needs |
| Faster API | $5 per million tokens | $25 per million tokens | Latency sensitive applications requiring maximum speed |
Comparing per token costs to competing models: Grok 3’s standard API pricing at $3 input/$15 output closely matches Anthropic’s Claude 3.7 Sonnet, positioning the models as direct competitors on cost. Google’s Gemini 2.5 Pro offers lower per token costs, making it a cheaper alternative for organizations prioritizing raw cost efficiency over the reasoning performance advantages Grok 3 provides. At typical usage volumes, a deployment processing 10 million tokens monthly (roughly 7.5 million words) would cost $180 for standard API or $300 for faster API, $18,000 or $30,000 annually respectively. At enterprise scale processing 100 million tokens monthly, costs reach $1,800 monthly ($21,600 annually) for standard API or $3,000 monthly ($36,000 annually) for faster API.
Batch processing economics favor applications that can accumulate requests and submit them together rather than requiring real time individual responses. The throughput capacity scales with concurrent request handling and context window utilization. Organizations with high volume applications should investigate whether batch processing discounts exist and structure workflows to maximize token efficiency. Strategies for optimizing API costs include implementing caching layers that store and reuse responses for common queries, prompt compression techniques that reduce input token counts without losing essential information, and careful context management that includes only necessary information within the context window rather than dumping entire documents.
ChatGPT Enterprise reportedly delivers over $10,000 monthly in potential savings through automated ticket handling for customer service organizations, providing context for ROI calculations across competing models. This reference point suggests enterprise deployments can justify substantial monthly API costs when automation delivers measurable labor savings, reduced response times, or improved customer satisfaction metrics.
Free tier benefits include DeepSearch and Think features available to all X platform users without payment, providing significant functionality for testing, prototyping, and low volume personal use. Premium+ exclusive features including Big Brain Mode may justify the $40 monthly cost for power users requiring enhanced reasoning on a regular basis, particularly given this subscription price falls well below enterprise API costs while providing unlimited use within the platform’s rate limits. Upgrading to paid API tiers becomes cost effective once monthly usage exceeds the free tier’s practical limits or when applications require programmatic integration rather than manual interface interaction.
Multimodal Capabilities and Context Window Performance
Extended context processing enables Grok 3 to analyze lengthy documents, maintain coherent multi-turn conversations, and synthesize information across diverse sources within a single inference request.
The model supports a standard context window of 128,000 tokens for typical operations, with extended capability reaching 1 million tokens when applications require analysis of full codebases, lengthy research papers, or extensive conversational history. This extended capacity matches Gemini 2.5 and GPT-4.1, positioning Grok 3 competitively for applications where context length determines usability. To provide scale: 128,000 tokens represents roughly 96,000 words or approximately 300 pages of text, while the 1 million token extended window accommodates roughly 750,000 words or 2,250 pages.
Supported input modalities and processing:
- Text analysis: processes long form documents with full context preservation across the entire content length
- PDF document processing: extracts and analyzes content from PDF files directly through Grok Studio integration
- Image analysis: interprets visual content including charts, diagrams, screenshots, and photographs
- X platform data integration: analyzes user profiles, post history, and engagement patterns with contextual awareness
- Planned voice/audio features: future release will add speech to text and voice mode for audio interaction
Multi-turn conversation performance earned first place in LMArena evaluations, demonstrating superior ability to maintain context, reference previous exchanges accurately, and build on established conversational threads without losing coherence. This capability proves critical for customer service applications where conversations span multiple questions, coding assistance sessions that iteratively refine solutions across several exchanges, and research dialogues that progressively narrow investigation scope through follow-up queries. The model tracks conversational state effectively, avoiding repetitive responses and maintaining awareness of user preferences expressed earlier in the dialogue.
Extended context windows enable several practical applications that shorter context limits make difficult or impossible. Analyzing full codebases allows the model to understand architectural decisions, trace function dependencies, and suggest refactoring strategies informed by the complete project structure rather than isolated code snippets. Processing lengthy research papers preserves arguments spanning dozens of pages, enabling accurate summarization and comparison without information loss from chunking strategies. Customer service conversations maintain full interaction history allowing agents (or automated systems) to reference previous issues, track resolution attempts, and avoid asking customers to repeat information. Document Q&A across multiple sources becomes feasible by loading several reference documents simultaneously and answering questions that require synthesizing information from all sources, particularly useful for legal analysis, policy review, and research literature surveys. Google Drive integration through Grok Studio streamlines document access, allowing users to directly load files from cloud storage rather than copying content manually.
Specialized Task Performance and Domain Expertise
Grok 3 received explicit training emphasis on mathematics and competitive coding, creating particular strengths in these domains, yet testing reveals unexpectedly strong cross domain performance.
While the model’s training focused specifically on math and competitive coding challenges, it outperforms other models in science and additional subjects beyond its primary training emphasis. This generalization suggests the reasoning capabilities developed for mathematical problem solving transfer effectively to scientific hypothesis evaluation, logical analysis, and systematic evidence assessment.
| Domain | Performance Level | Key Applications |
|---|---|---|
| Software development | Strong (15% improvement) | Code generation, debugging, architecture analysis, refactoring assistance |
| Mathematical research | Leading (93% AIME) | Problem solving, proof assistance, competition level challenges |
| Scientific analysis | Strong (85% GPQA) | Graduate level physics, chemistry, biology problem solving |
| Market analysis | Competent | Trend identification, prediction generation, financial modeling support |
| Medical diagnosis assistance | Competent (requires verification) | Differential diagnosis generation, literature synthesis, case analysis |
| Fraud detection | Competent | Pattern recognition, anomaly detection, transaction analysis |
The DeepSearch feature provides research quality information retrieval comparable to Perplexity’s Deep Research functionality, though testing shows it ranks below OpenAI’s research capabilities. When you activate DeepSearch, the model queries web sources, synthesizes information from multiple results, and provides answers grounded in current information rather than relying solely on training data. This proves particularly valuable for market analysis applications requiring current pricing data, news events, or competitive intelligence. The ability to analyze X platform data (user profiles, post history, and engagement patterns) adds unique contextual information unavailable to competing models, enabling social media analysis, brand monitoring, and trend identification based on actual platform activity.
Practical deployment examples demonstrate real world application across industries. Code generation workflows benefit from the 15% improvement in resolving complex programming challenges, with developers reporting 30% workflow efficiency gains when using Grok 3 for code analysis and generation. Research assistance pipelines use DeepSearch for literature discovery combined with the extended context window for analyzing full papers. Financial analysis automation applies market prediction capabilities to trading signals, risk assessment, and portfolio optimization, though users should verify outputs given the documented hallucination risks. Healthcare support applications can generate differential diagnoses and synthesize medical literature, but the model’s limitations with citation accuracy create serious concerns for clinical deployment. All medical applications require expert verification before any clinical decision making.
For a comprehensive comparison of how Grok 3 performs against ChatGPT across different task categories and use cases, see this ChatGPT vs Grok 3 comparison analyzing domain specific strengths and practical deployment considerations.
Organizations should recognize both the strengths and limitations when deploying for specialized domains. While Grok 3 demonstrates strong general capability across diverse fields, specialized domain models trained specifically on medical literature, legal corpora, or industry specific datasets may still outperform in narrow expert applications requiring deep domain knowledge beyond what general training provides.
Safety Features and Content Filtering Performance
xAI implemented AI alignment safeguards designed to prevent bias, misinformation, and manipulation in model outputs.
These safety mechanisms include content filtering that blocks harmful requests, bias detection systems that monitor outputs across demographic categories, fact checking processes that attempt to verify factual claims, and output consistency checks that ensure responses remain stable across similar prompts for sensitive topics. The implementation appears relatively conservative based on testing results showing limited creativity and repetitive responses in domains like humor generation, suggesting safety filters may constrain output diversity to avoid potential offensive content.
Safety evaluation across key areas:
- Bias testing: monitors outputs for demographic bias, though comprehensive third party audit results aren’t yet publicly available
- Toxicity filtering: blocks generation of harmful, offensive, or dangerous content with documented effectiveness in standard test cases
- Fact checking and citation accuracy: attempts to verify claims but shows documented weakness with URL hallucination and invented fake citations
- Harmful content prevention: refuses requests for illegal information, dangerous instructions, or explicit content with high consistency
- Output consistency: maintains similar responses across similar prompts in sensitive contexts, avoiding unpredictable behavior
The documented hallucination issues with citations and fake URLs present the most significant safety concern for production deployment. When asked to provide sources for factual claims, the model generates references that appear legitimate but don’t exist, inventing author names, publication titles, URLs, and dates that cross checking reveals as fictional. This behavior occurs frequently enough that applications requiring verifiable sources need independent citation verification workflows. Organizations deploying Grok 3 for research, compliance, journalism, or any domain where source accuracy matters should implement automated checking against actual reference databases or manual verification by human reviewers before treating citations as valid.
Severity of hallucination issues varies by prompt structure and domain. Requests for obscure academic papers or niche technical documentation show higher hallucination rates than mainstream topics with abundant training data coverage.
Final Words
Grok 3 model performance places it firmly in state-of-the-art territory with 93% AIME accuracy, 1402 Chatbot Arena ELO, and 3x speed gains over its predecessor.
The 2.7 trillion parameter model delivers measurable advantages: 0.8-second code generation, 25% faster responses, and first-place rankings in instruction following and multi-turn conversations.
Real-world testing confirms strong reasoning capabilities through Think Mode and Big Brain features, though limitations exist in complex coding and citation accuracy.
For developers evaluating production deployment, the $3/$15 API pricing, 1 million token context window, and multimodal capabilities through Grok Studio provide compelling value despite gaps behind GPT-4o in specific tasks.
FAQ
Q: What is the performance benchmark of Grok 3?
A: Grok 3 performance benchmarks include 93% accuracy on AIME 2025 math tests, 85% on GPQA science evaluations, and a 1402 ELO score on Chatbot Arena’s leaderboard. The model outperforms Gemini 2.0 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and o3-mini across mathematical reasoning, scientific problem-solving, and coding tasks.
Q: Why is Grok 3 so fast?
A: Grok 3 is so fast because it was trained using 10-15x more compute power than Grok 2 on 100,000-200,000 NVIDIA H100 GPUs at xAI’s Memphis supercomputer. This massive infrastructure investment produces 3x faster performance than its predecessor and 25% quicker responses than similar models, with 0.8-second average response times for code generation.
Q: What tasks can Grok 3 perform well?
A: Grok 3 performs well on mathematical reasoning, code generation in Python, C++, and JavaScript, scientific problem-solving, and multi-turn conversations. It achieved first place on LMArena across all categories including coding, math, creative writing, instruction following, and longer queries, with particular strength in solving fresh AIME 2025 math competition problems.
Q: Is Grok 3 actually better?
A: Grok 3 is actually better than most current models, scoring higher than Gemini 2.0 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and GPT-4o on key benchmarks. Former Tesla AI Director Andrej Karpathy places it “somewhere around state of the art territory” comparable to OpenAI’s o1-pro, though it still lags behind OpenAI’s o3 model in head-to-head comparisons.
Q: How much does Grok 3 API access cost?
A: Grok 3 API access costs $3 per million input tokens and $15 per million output tokens for the standard version, or $5 per million input tokens and $25 per million output tokens for the faster version. X Premium+ subscription access costs $40 per month, while DeepSearch and Think features are available free to all X platform users.
Q: What is Grok 3’s context window capacity?
A: Grok 3’s context window capacity is 128,000 tokens as standard, with extended capability reaching 1 million tokens, matching Gemini 2.5 and GPT-4.1. This allows analysis of full codebases, lengthy research papers, and extended conversational context while maintaining accuracy across multi-turn conversations where it scored first place on LMArena evaluations.
Q: What are Grok 3’s main limitations?
A: Grok 3’s main limitations include struggling with complex coding compared to GPT-4o and Claude, hallucinating citations and inventing fake URLs, limited creativity with repetitive joke responses, and failing certain specialized challenges like Unicode emoji mysteries that DeepSeek R1 solved. It also ranks below OpenAI in Deep Search capabilities despite matching Perplexity’s Deep Research quality.
Q: How do I access Grok 3?
A: You can access Grok 3 through three methods: the grok.com website, the X platform Grok icon at bottom right or left-side panel, or SuperGrok subscription for dedicated website and app access. API access launched April 9, 2025 for developers, while free access with DeepSearch and Think features is available to all X platform users.
Q: What is Think Mode in Grok 3?
A: Think Mode in Grok 3 provides detailed step-by-step reasoning for STEM professionals using chain-of-thought logic that explains the thought process before responding. It processes complex scenarios like the trolley problem in 52 seconds and helps the model lead AIME 2025 benchmarks when given more thinking time for multi-step mathematical and analytical problems.
Q: What programming languages does Grok 3 support?
A: Grok 3 supports Python, C++, and JavaScript code execution through Grok Studio with Google Drive integration. The model resolves complex programming challenges 15% more effectively than earlier benchmarks, successfully demonstrated capabilities by building a Tetris game during demos, and performs strongly on structured logic problems though it struggles with complex coding compared to GPT-4o and Claude.
Q: What future features are planned for Grok 3?
A: Future features planned for Grok 3 include Super Grok premium subscription tier, voice mode assistant, persistent memory features, and 5x more powerful training infrastructure expansion. Voice mode and audio-to-text capabilities are planned for future release, with SpaceX planning to send Grok 3 to Mars in November 2026 aboard StarShip rockets with Optimus robots.
Q: How does Grok 3 pricing compare to competitors?
A: Grok 3 pricing is comparable to Anthropic’s Claude 3.7 Sonnet but more expensive than Google’s Gemini 2.5 Pro. The $3/$15 standard API pricing and $5/$25 faster API pricing positions it in the premium tier alongside Claude, while offering free access to DeepSearch and Think features for all X users and Big Brain Mode exclusively for Premium+ subscribers at $40 monthly.

{kind=link}