

Who decides which zero‑day gets fixed first — the loudest pager or the smartest score?
In the first hours after discovery you need a fast, clear way to rank risk so your team knows whether to stop everything or watch and wait.
This post lays out practical prioritization methods: quick triage of exploitability and exposure, plus how to combine CVSS, EPSS, and FAIR to steer immediate containment and executive decisions.
Read on for a step‑by‑step approach you can run in the first hour.
How to Quickly Assess Zero‑Day Vulnerability Severity

Zero‑day vulnerabilities don’t give you time to prepare. The first few hours after discovery are what matter. You need triage that’s fast and focused on the factors that actually indicate real risk. A structured approach keeps you from spinning in circles and helps you decide whether to drop everything or keep monitoring while you handle other priorities.
Effective zero‑day severity evaluation comes down to three things: exploitability, exposure, and what attackers are actually doing. Start here:
- Check for active exploitation evidence. Search threat intelligence feeds, vendor advisories, and security mailing lists for proof‑of‑concept code, exploit kits, or confirmed attacks in the wild.
- Identify affected asset criticality. Figure out whether the flaw touches authentication systems, customer‑facing platforms, payment infrastructure, or other high‑value targets that would halt operations if compromised.
- Measure exposure level. Is the vulnerable service internet‑facing? Reachable only from internal networks? Isolated behind multiple security controls?
- Evaluate privilege requirements and attack prerequisites. Does exploitation require user interaction, existing credentials, or physical access? Or can someone execute remotely without authentication?
Teams that run this triage within the first hour can make informed containment decisions before attackers move laterally. If active exploitation is confirmed and the asset is both critical and exposed, immediate isolation or temporary mitigation becomes your top priority. When exploitation is theoretical and the asset is segmented or low‑value, you can shift to planned patching timelines and compensating controls while monitoring for changes in threat activity.
Methodologies for Scoring Zero‑Day Risk

Organizations rely on quantitative scoring to compare vulnerabilities and allocate limited security resources. For zero‑days, traditional models often fall short because they were designed for disclosed, patched flaws with known attack patterns.
CVSS
The Common Vulnerability Scoring System assigns a numeric score based on attack vector, complexity, required privileges, user interaction, and impact to confidentiality, integrity, and availability. CVSS scores range from 0 to 10, with critical vulnerabilities scoring 9.0 or higher. The model works well for comparing similar vulnerabilities. But it struggles with zero‑days because it doesn’t account for actual exploitation likelihood or the presence of active attacks.
EPSS
The Exploit Prediction Scoring System uses machine learning to estimate the probability that a vulnerability will be exploited in the next 30 days. EPSS incorporates threat intelligence, exploit availability, and historical patterns to produce a likelihood score between 0 and 1. Unlike CVSS, EPSS prioritizes based on what attackers are doing, not just what they could do.
FAIR
Factor Analysis of Information Risk quantifies cyber risk in financial terms by modeling loss event frequency and loss magnitude. FAIR helps you translate zero‑day exposure into dollar estimates for downtime, breach costs, regulatory fines, and recovery expenses. This approach supports executive decision‑making when comparing security investments or deciding whether to accept residual risk.
| Model | Strengths | Limitations |
|---|---|---|
| CVSS | Standardized, widely understood, technical depth | Ignores exploitation likelihood and active threat context |
| EPSS | Predicts real‑world exploitation, continuously updated | Does not measure business impact or asset criticality |
| FAIR | Quantifies financial impact, supports risk‑based budgeting | Requires detailed asset valuation and loss modeling |
Combining these models produces more accurate prioritization. Use CVSS for technical severity, EPSS for exploitation probability, and FAIR to estimate business‑level consequences.
Evaluating Exploitability and Threat Actor Capabilities

Exploitability measures how easily an attacker can turn a vulnerability into working code that achieves their objective. Technical factors include whether the flaw allows remote execution without authentication, requires user interaction like opening a file, or depends on chaining multiple weaknesses. Vulnerabilities that permit remote code execution with no prerequisites rank highest. Attackers can weaponize them at scale. Local privilege escalation flaws are serious but require the attacker to already have a foothold, reducing immediate risk unless paired with another entry point.
Threat actor sophistication shapes how quickly a zero‑day becomes dangerous.
State‑aligned groups and advanced persistent threat actors often stockpile zero‑days and deploy them selectively against high‑value targets, sometimes months before public disclosure. These actors have the resources to develop custom exploits, maintain operational security, and evade detection. Cybercriminal groups acquire zero‑days from exploit brokers or underground markets, then use them in ransomware campaigns or data theft operations. When a zero‑day appears in mass exploitation or is sold on dark‑web forums, the risk to a broad range of organizations jumps immediately.
Assessing exploitability and attacker intent together produces a clearer picture of urgency. A technically easy remote exploit combined with confirmed use by ransomware operators demands immediate action. A complex local vulnerability with no observed exploitation and limited attacker interest can follow a normal patch cycle with compensating controls in place until the fix is tested and deployed.
Business and Operational Impact Analysis for Zero‑Day Exposure
Zero‑day vulnerabilities don’t affect all organizations equally. Impact depends on which systems are vulnerable, how critical those systems are to daily operations, and what data or functions they control. A flaw in an authentication platform can lock users out of essential services, halt customer transactions, and expose credentials across the entire environment. Vulnerabilities in customer‑facing applications risk data breaches, regulatory penalties, and long‑term reputation damage.
Critical assets include any system whose compromise or downtime would stop revenue, violate compliance requirements, or create safety risks. Production infrastructure, payment gateways, identity management platforms, and cloud control planes all fall into this category. Zero‑days targeting these assets require the fastest response. Downtime or breach costs scale quickly, often reaching millions of dollars per hour for large enterprises.
High‑impact business effects from zero‑day exploitation include:
- Revenue loss from system downtime or halted transactions
- Regulatory fines and mandatory breach notifications under GDPR, HIPAA, or PCI DSS
- Theft of intellectual property, customer data, or financial records
- Operational disruption when attackers encrypt or destroy critical files
- Legal liability and class‑action lawsuits following customer data exposure
Impact analysis should produce a risk score that multiplies technical severity by business criticality. A medium‑severity vulnerability in a core authentication system outranks a critical‑severity flaw in a low‑value development server. Quantifying impact in terms of revenue, compliance, and operational continuity helps security teams justify emergency patching windows and resource allocation to executives who need to understand business consequences, not just CVE scores.
Telemetry, Detection Signals, and Indicators of Exploitation

Detecting zero‑day exploitation before significant damage occurs requires behavioral monitoring. Signature‑based defenses can’t catch attacks that use unknown code. Endpoint telemetry reveals unusual process execution patterns, such as legitimate binaries spawning unexpected child processes, memory injections, or attempts to disable security tools. Anomalous outbound network connections, especially to newly registered domains or IP addresses with no prior organizational history, often signal command‑and‑control communication after initial compromise.
Network telemetry highlights abnormal traffic volumes, protocol misuse, and lateral movement attempts.
Privilege escalation indicators include repeated authentication failures followed by sudden success, access to sensitive directories by accounts that normally don’t touch those resources, and credential dumping tools running on endpoints. Cloud environments generate logs from API calls, configuration changes, and identity events. Unusual API usage patterns, such as bulk data exports or privilege modifications outside business hours, can indicate zero‑day exploitation in cloud infrastructure.
Threat hunting teams combine these signals with threat intelligence to identify zero‑day activity. They look for behaviors that match known attack chains even when the specific exploit is new. Successful detection relies on centralized logging, baseline behavior models, and machine learning systems that flag deviations from normal patterns. Organizations that invest in continuous monitoring and proactive threat hunting reduce the window between initial exploitation and containment, limiting the attacker’s ability to move laterally, establish persistence, or exfiltrate data.
Incident Response Frameworks for Zero‑Day Events
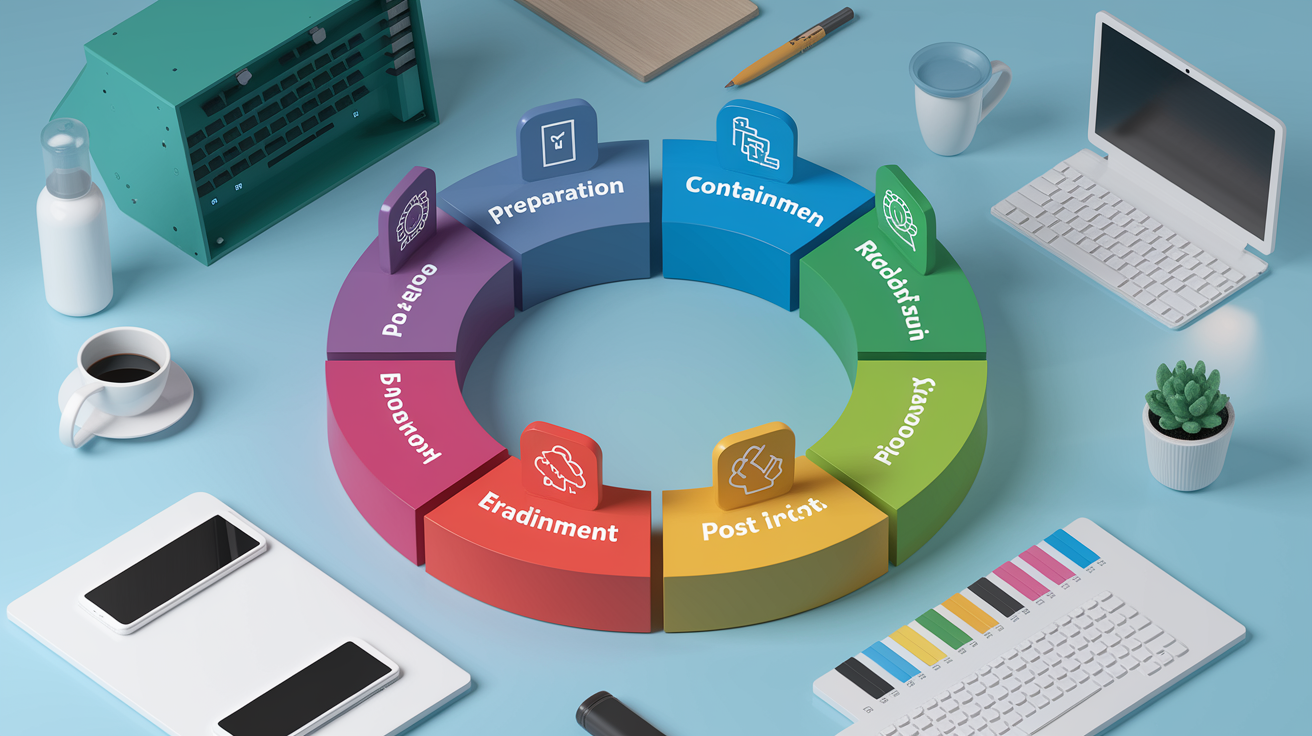
Incident response frameworks provide structure when speed and coordination matter most. The NIST Cybersecurity Framework outlines six phases: preparation, detection and analysis, containment, eradication, recovery, and post‑incident activity. Zero‑day events compress timelines and demand cross‑functional teamwork because patches may not exist and compensating controls must be deployed quickly.
Preparation means maintaining updated asset inventories, documented network diagrams, and pre‑approved containment actions so teams can act without waiting for executive sign‑off. When zero‑day exploitation is detected, immediate actions include:
- Isolate affected systems. Disconnect vulnerable hosts from the network or place them in a monitored VLAN to prevent lateral movement while preserving forensic evidence.
- Assess scope. Identify all systems running the vulnerable software, check logs for signs of compromise, and determine whether attackers have established persistence or moved beyond the initial entry point.
- Deploy temporary mitigations. Apply firewall rules, disable vulnerable services, enforce stricter access controls, or enable additional logging until a patch is available.
- Coordinate communication. Notify security operations, IT operations, legal, affected business units, and external partners. Assign a single incident commander to reduce confusion and ensure consistent updates.
After containment, eradication removes attacker access and persistence mechanisms. Recovery restores affected systems to known‑good states, applies patches or compensating controls, and validates that monitoring tools detect no further malicious activity. Post‑incident reviews identify gaps in detection, response time, or asset visibility, then feed lessons back into preparation and training. Organizations that run tabletop exercises for zero‑day scenarios respond faster and with fewer coordination failures when real incidents occur.
Prioritizing Remediation and Mitigation for Zero‑Days

Not all zero‑days can be patched immediately. Vendors may need days or weeks to develop, test, and release fixes. During that window, you must prioritize which systems receive temporary mitigations first and which can accept residual risk. Prioritization depends on exploitability, asset criticality, exposure level, and the availability of effective compensating controls.
High‑priority remediation targets include internet‑facing services, authentication platforms, and systems that store sensitive data or control critical infrastructure. These assets should receive temporary mitigations within hours of zero‑day disclosure. Lower‑priority systems, such as internal development environments or isolated legacy equipment, can follow standard patch cycles if they’re already segmented and protected by multiple defensive layers.
Temporary mitigations that reduce zero‑day risk include:
- Network segmentation to isolate vulnerable systems from high‑value assets and prevent lateral movement
- Privilege reduction by removing administrative rights from service accounts and limiting user permissions to least‑privilege baselines
- Web application firewall rules that block known attack patterns or suspicious input, even if the underlying vulnerability remains unpatched
- Virtualization isolation or micro‑segmentation that restricts communication between workloads, limiting blast radius if one host is compromised
Patching timelines vary by vendor responsiveness, internal testing requirements, and operational constraints. Critical vulnerabilities with active exploitation and public proof‑of‑concept code should be patched within 24 to 72 hours if feasible. High‑severity flaws with no observed exploitation can follow a one‑week cycle, and medium‑severity issues align with standard monthly patch windows unless threat intelligence changes the risk profile. Always verify patch installation and test functionality after deployment. Failed patches are a common cause of repeat breaches.
Communication and Reporting Guidelines During Zero‑Day Incidents

Clear communication during zero‑day events reduces operational confusion and ensures decision‑makers have the information they need to allocate resources and approve emergency actions. Internal updates should reach security operations, IT operations, legal, communications, and affected business units within the first hour of confirmed exploitation. Periodic status reports every four to six hours keep stakeholders informed as the situation evolves, covering affected asset counts, containment actions taken, estimated time to remediate, and any changes in threat intelligence.
Executive reporting translates technical details into business impact. Leaders need to know how many systems are vulnerable, what data or services are at risk, whether customer operations are affected, and what the incident response team is doing to mitigate harm. Reports should include risk scores, financial impact estimates when available, and clear next steps. Avoid jargon. Focus on outcomes such as “authentication system isolated to prevent credential theft” rather than “implemented VLAN segmentation on LDAP infrastructure.”
Regulatory disclosure requirements vary by industry and jurisdiction. GDPR mandates notification within 72 hours of becoming aware of a personal data breach. HIPAA requires covered entities to report breaches affecting 500 or more individuals to the Department of Health and Human Services. Financial services organizations may need to notify regulators, customers, and credit bureaus depending on the type of data exposed. Legal teams should be involved early to determine notification obligations and coordinate public statements. Accuracy matters more than speed in external communications because incorrect information erodes trust and can create additional legal liability.
Final Words
In the action, we ran through rapid triage, scoring models (CVSS, EPSS, FAIR), exploitability and threat‑actor signals, impact analysis, telemetry, incident response steps, remediation priorities, and communication guidelines.
Start by checking exploitability, asset criticality, exposure level, and signs of active exploitation, then fold scoring and business impact into your priorities.
Use this zero day vulnerability impact assessment as a practical checklist: triage fast, apply temporary controls, coordinate response, and keep stakeholders informed. Do that and you’ll reduce risk and recover more quickly.
FAQ
Q: What is zero-day vulnerability explained?
A: A zero-day vulnerability is a software or hardware flaw unknown to the vendor and without a patch, allowing attackers to exploit it immediately; it demands rapid detection, assessment, and mitigation.
Q: What are the 4 stages of vulnerability assessment?
A: The four stages of vulnerability assessment are discovery (finding flaws), analysis (validating and characterizing), prioritization (scoring risk and urgency), and remediation (applying fixes or temporary mitigations).
Q: Is it legal to find zero-day vulnerabilities?
A: Finding zero-day vulnerabilities is legal when done with permission, in authorized bug-bounty programs, or under coordinated disclosure; unauthorized probing or exploitative use can violate laws and contracts.
Q: What is a zero-day vulnerability NIST?
A: According to NIST, a zero-day vulnerability is a flaw unknown to the vendor with no available patch, creating elevated risk until detection, mitigation, or patch deployment reduces exposure.

{kind=link}